关于昨天应该涨多少这件事,Tushare 和 东财还没商量好
最后更新: 2025-11-24
Table of Content
最近在整一个适合个人使用的量化框架,数据源选择了 tushare,实时数据和交易 API 会使用 QMT。在尝试一个策略时,发现该发出信号的时候,没有发出信号,于是就开始了排错之旅。这一查不要紧,发现就连最基本的每日涨跌幅数据也算不『对』了。
昨天该涨多少,还没想好¶
import akshare as ak import tushare as ts import pandas as pd import matplotlib.pyplot as plt import time
start = "20240101" end = "20241231"
symbol_ak = "000001" symbol_ts = "000001.SZ"
pro = ts.pro_api()
作为一个量化框架,必须要有本地数据存储的能力。在行情数据上,一般我们存储不复权数据和复权因子,在使用时,根据需要的复权类型实时计算。
在 tushare 中,我们通过 pro.daily 接口获得每日未复权价格和每日涨跌幅:
1 2 3 4 5 | |
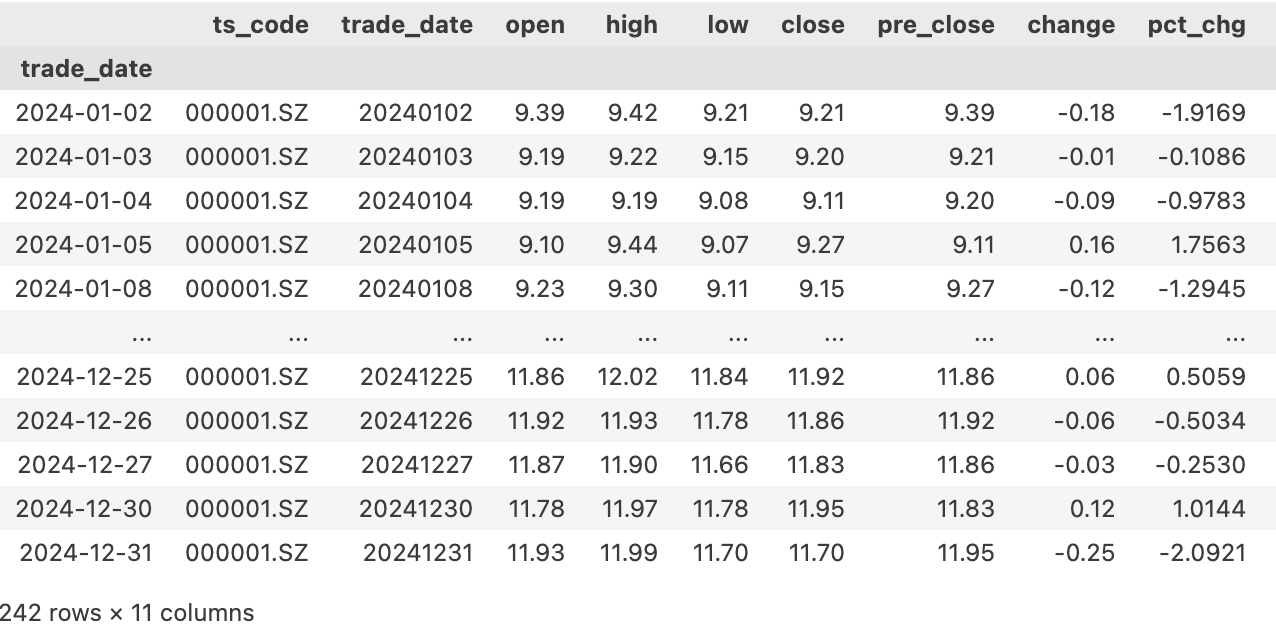
但是,我拿着这个涨跌幅数据与东财一对比,发现问题来了:
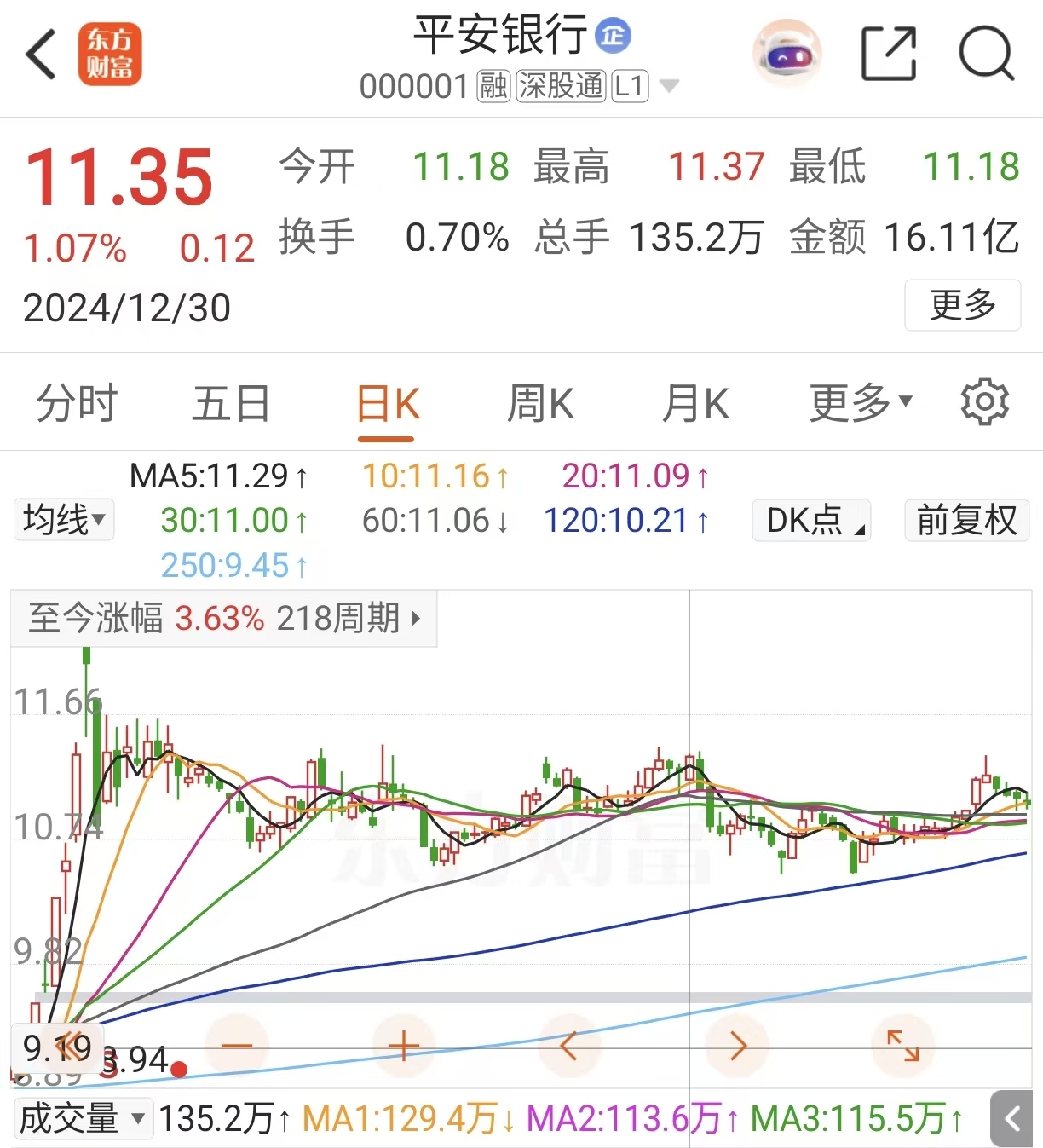
在去年12月31日这天,东财认为平安银行涨了1.07%,而 tushare 认为平安银行应该涨 1.01%。这还不是差距最大的。差距最大的一天是2月11日,tushare 认为平安银行上涨9.97%,东财则认为它上涨了11.86%,相差2个点。
一支股票,一天既能涨1%,又能涨2%,还都是权威的软件给出的,这是不是太魔幻了?!
涨跌幅是怎么算的?¶
理论上,涨跌幅就是T+1日的收盘价除以 T日的收盘价减去1;考虑到除权因素,我们需要先对收盘价进行复权,然后再才能计算涨跌幅。实际上,复权处理只影响除权日当天涨跌幅。所以,在未发生除权时,使用未复权价计算出来的涨跌幅与经过复权处理后,计算出来的涨跌幅是完全一致的。
下面我们就来检验一下。这里要用到adj_factor接口来获取个股的复权因子。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
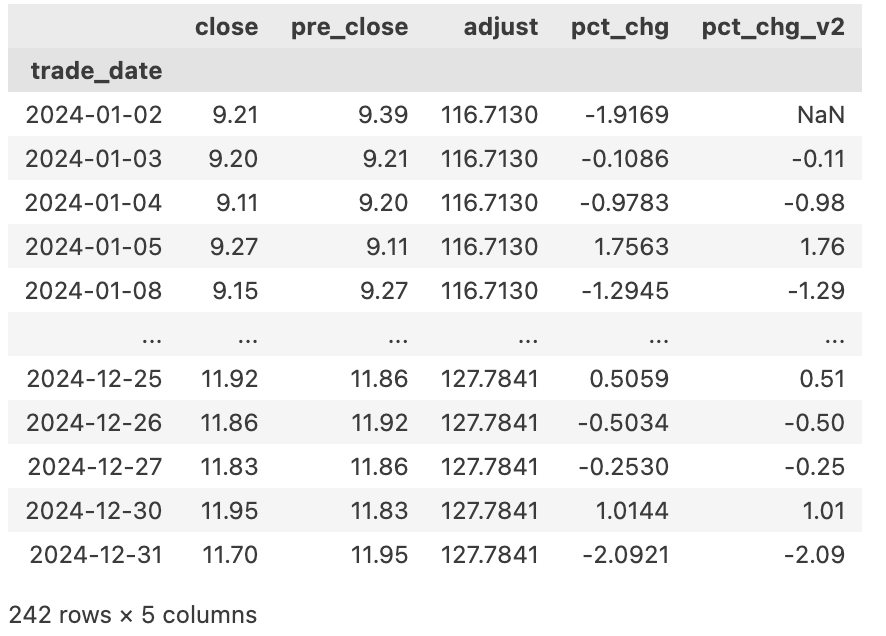
可以看出,tushare接口daily中的每日涨跌幅,就是复权后的收盘价计算出来的涨跌幅。我们可以通过下面的代码来可视化地显示两个序列之间的差异:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | |
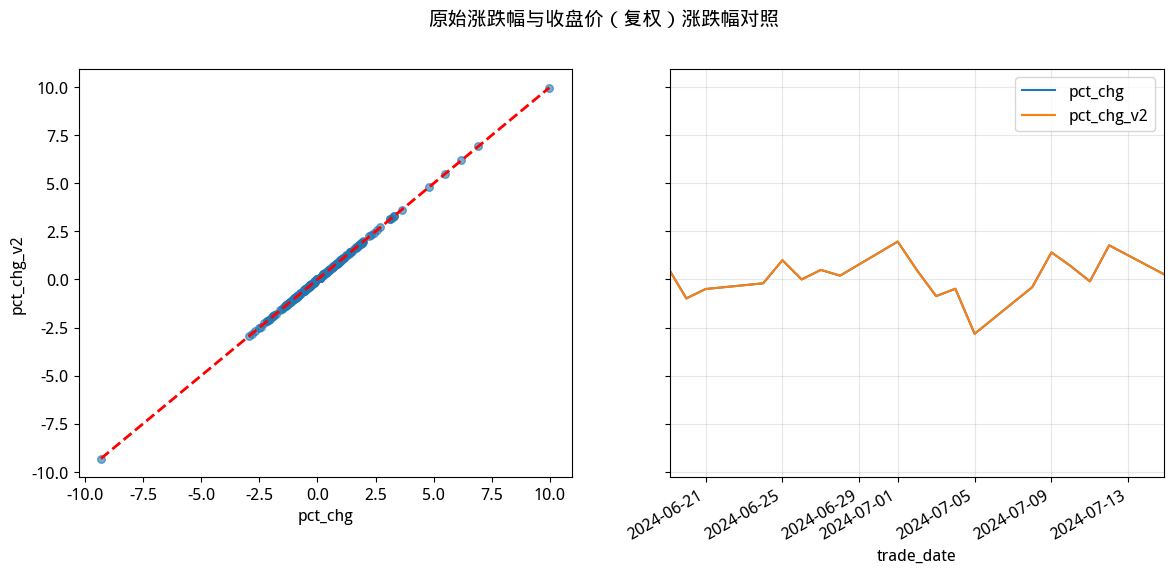
显然,两个序列完全相同。这说明,我们可以不依赖daily接口返回的每日涨跌幅,而是仅用保存的未复权收盘价和复权因子来计算每日涨跌。这与大多数教程(及量化框架)上介绍的方法是一致的。
既然计算方法没错,那么,tushare 中涨跌幅与东财不一致的情况,会不会是个别的误差?
请 akshare 出庭作证¶
通过行情软件逐 bar 比较数据终究是太笨了。我们需要更高效的方法拿到行情软件的数据。对于东财的数据,最可靠的方法就是通过akshare。
在 akshare 中,我们通过 stock_zh_a_hist 来获取行情数据。该接口会通过『涨跌幅』字段来返回每日涨跌幅。在仔细阅读 akshare 的文档时,我意外地发现,在三种复权模式下,官方文档给出的示例中,涨跌幅居然是不一样的!
下面,我们将通过三种复权方式来获得所有的涨跌幅数据,让大家直观地感受一下。
以下内容要使用 akshare,受爬虫机制限制,在匡醍研究平台中,可能运行不稳定。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | |
这样我们就得到了akshare 下各种涨跌幅。
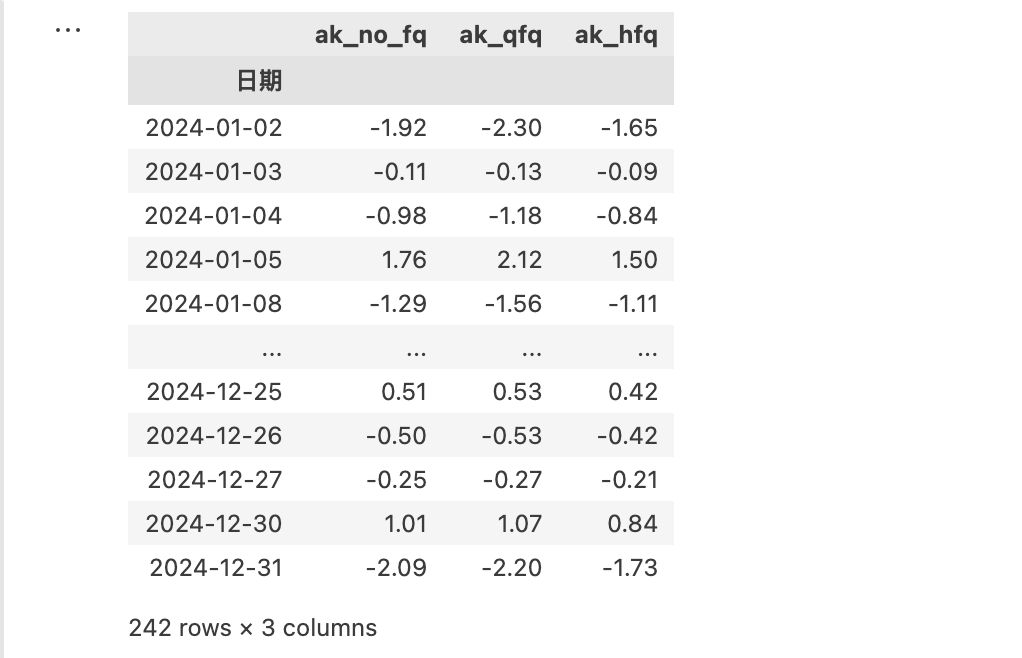
由于 akshare 的数据是通过抓取东财网页(含 API) 得来的,所以,我们实际上拿到的就是东财行情软件的数据。在这些数据中,前复权列下的涨跌幅,与我们在东财软件中看到的是一致的,所以,让我们就把这一列,与前面得到的 tushare 的涨跌幅数据进行比较:
compare(df_ak, "ak_qfq", "pct_chg", df_ts, title="ak 前复权 vs tushare")
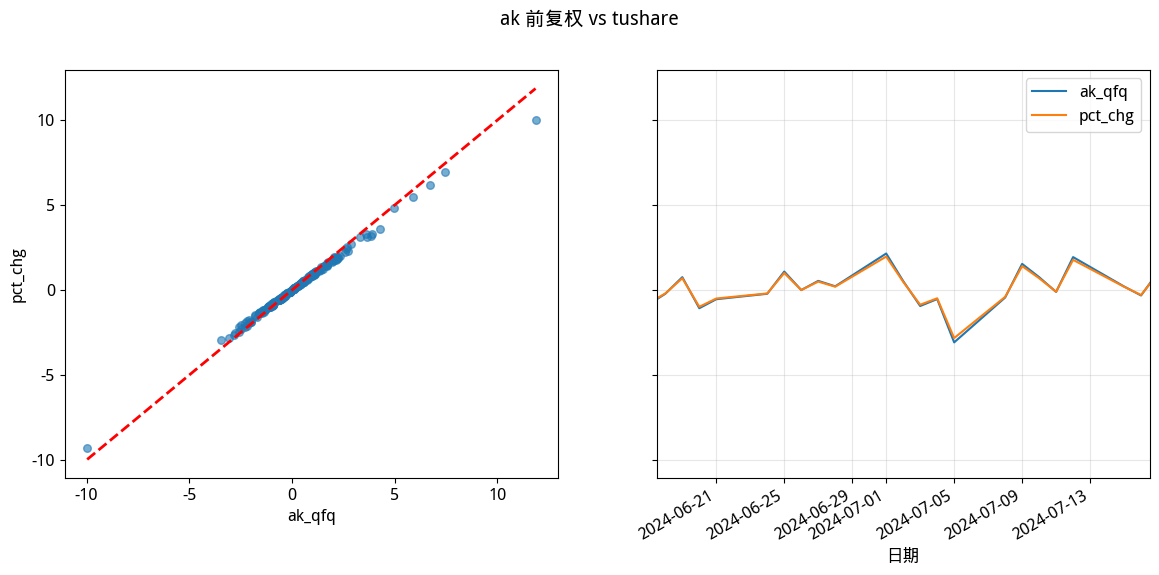
可以看出,两个涨跌幅基本上是不一致的。问题是,东财对还是 Tushare 对?
答案就在akshare 得到的涨跌幅数据上。我们知道,对同一品种的同一天,个股不可能有多个涨跌幅,对涨跌幅进行复权是没有任何意义的;通过各种复权后,计算出来的涨跌幅,在未发生除权的日期,涨跌幅应该与未复权是一致的。
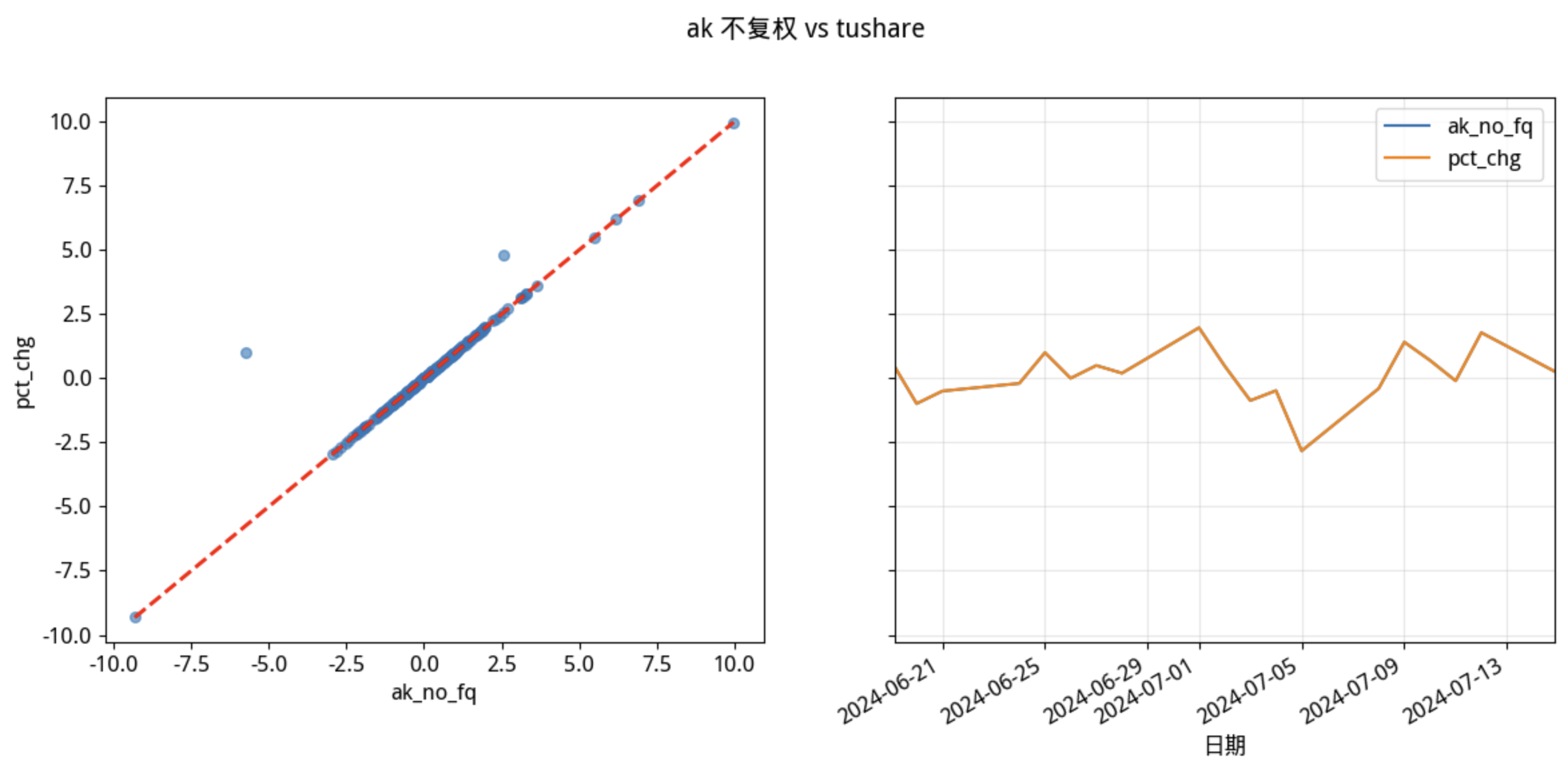
现在,我们就拿 akshare 中未复权的涨跌幅与 tushare的涨跌幅进行对比。
compare(df_ak, "ak_no_fq", "pct_chg", df_ts, title="Akshare 不复权 vs tushare")
从左图中可以看出,仅有两个点不同。
Info
请忽略右图。右图本应该显示两个点不同,因为显示空间的原因,它们被绘图『吞掉』了。
最后的证明¶
在 tushare的daily接口中,还会返回 pre_close数据。
1 2 3 4 5 | |
通过 close/pre_close 计算出来的涨跌幅与日涨跌完全一致。而它的未复权的close与pre_close又都是正确的。所以,Tushare的数据是正确的。而东财的数据(或者说你通过 akshare得到的数据)则会与我们的期望不一样。它的未复权下的涨跌幅,是真正的未复权: 如果个股昨天实收5元,今天开盘上涨10%,但发生1:1除权,所以实收价是2.75,东财会把涨跌幅计为-45%。
但是,它的前复权涨跌幅(这是我们打开行情软件,默认的视图)则是经过了某种处理(我不清楚是不是复权),因此,在我写下本文的这一刻,你看到的平安银行在2024年2月11日,它当天实际上涨9.97%,但会在东财软件上显示上涨了『11.86%』。东财这样处理当然有它的理由,不过从量化人的角度来看,可能并不符合我们的期望。
有一句话叫谁掌握了历史,谁就掌握了未来;谁掌握了现在,谁就掌握了历史。在东财的默认视图中,事情似乎正是这样。不过,量化人相信,个股的涨跌幅应该是一个确定不变的值。它不应该随着时间的推移而发生改变,它不是薛定谔的猫,在不同的时间观察它,就会得到不一样的结果。
在前面我们已经得到了 tushare 的复权数据。我们可以通过下面的图,直观地找出除权发生的日期:
1 | |
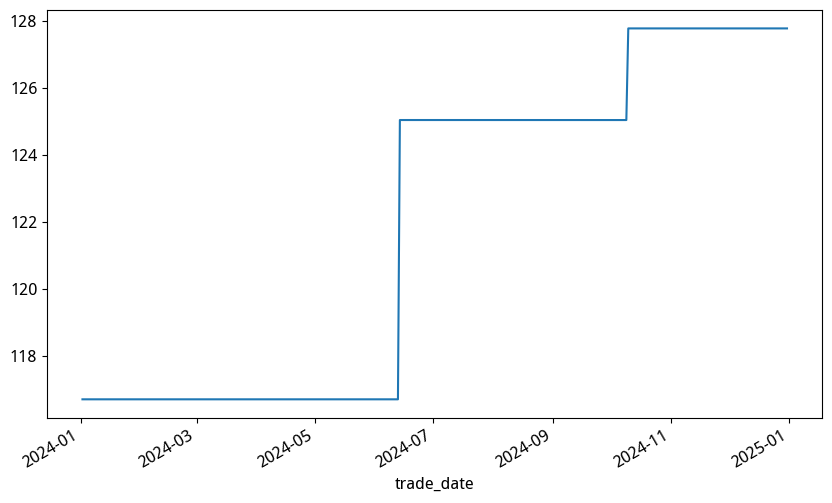
在 『Akshare 不复权 vs Tushare』 那个图中,游离于基准线上的两点,正对应这两个跳跃。
量化是一门精准的学问,需要我们以特别地耐心,去拷问每一个细节。通过今天的讨论,你知道了通常东财的数据非常精准;但如果你使用它返回的每日涨跌幅(无论是基于不复权还是复权)来作为训练的 target,那么就会引入重大的系统性偏差。
在这条路上,你需要匡醍和
结语¶
量化是一门精准的学问,需要我们以特别的耐心,去拷问每一个细节。通过今天的讨论,你知道了数据的差异可能会引入系统性偏差,也明白了如何通过复权因子和数据对比来验证数据的可靠性。
如果你对量化交易充满兴趣,想要深入了解如何挖掘因子、构建策略、优化模型,不妨加入我们的 量化24课。这是一门专为量化爱好者设计的课程,从基础到进阶,带你全面掌握量化交易的核心技能。让我们一起探索量化的世界,发现更多的可能性!