为什么我们需要因果卷积?
最后更新: 2026-03-26
Table of Content
为什么我们需要因果卷积?¶
市场的波动极其复杂。但在写量化策略的初期,我们几乎都会陷入一种对“完美参数”的执念,试图用最简单的指标去在市场里找到某种确定性。
在写量化策略的初期,我们几乎都会陷入一种对“完美参数”的执念中。
不管是 MA(移动平均)、MACD 还是布林带,我们总是在回测引擎里疯狂枚举,试图找到那个能完美拟合历史的数字:均线到底该用 20 日,还是 30 日?
然而,当我们把那个通过网格搜索找出来的“最优参数”挂上实盘时,结果往往大打折扣。
因为市场是活的,短期博弈、中期趋势和长期宏观周期每天都在以不同的比例混合。固定的参数,根本接不住这种混沌的变化。
这篇文章里,我们聊聊怎么用因果卷积(Causal Convolution)让模型自己从 K 线里"炼"出一组权重。
因果卷积是来自于 2016 年 DeepMind 的一篇论文 WaveNet: A Generative Model for Raw Audio。
为了解决语音生成中“不能偷看未来数据”的问题,Van Den Oord等人将普通卷积改造为因果卷积(配合扩张卷积),确保模型仅依赖历史信息生成下一时刻的音频样本。

解构均线:用完美的指数曲线去框定不确定的市场,是人类的傲慢¶
为了理解因果卷积,我们不妨先换个视角,重新审视一下我们最熟悉的均线。
拿 MA5 来说,它是把过去 5 天的收盘价加起来除以 5。
在数字信号处理的语境里,这就是一个权重全是 1/5 的滑动滤波器。它非常民主,五天内的数据人人平等。
但稍微有点交易经验的人都知道,昨天刚发生的大阴线,和五天前的一根十字星,对今天走势的指导意义能一样吗?
显然,越近的数据越包含核心信息。
于是,量化先驱们引入了 EMA(指数移动平均)。EMA:它认为历史永远在起作用,所以它不丢弃任何一根 K 线;但它又规定,信息的价值必须随着时间过去而指数级成倍衰减。
但在这里,我们其实犯了一个“人为的傲慢”的错误:凭什么市场情绪的衰减,必须是一条完美、平滑的指数曲线?
如果三天前美联储意外加息,或者非农数据大爆,那一天的 K 线权重,理应比波澜不惊的昨天大得多。EMA 这种写死了规则的数学公式,根本处理不了这种权重分配的“跳跃”。
从数学上看,不论是 MA 还是 EMA,本质上都是在计算一个卷积: $$ y_t = \sum_{i=0}^{k-1} w_i \cdot x_{t-i} $$ 对于 MA,权重 \(w_i\) 全是 \(\frac{1}{k}\);对于 EMA,权重 \(w_i\) 是按 \(\alpha(1-\alpha)^i\) 指数衰减的固定值。
问题来了:凭什么市场情绪的衰减必须是指数曲线?如果三天前美联储意外加息,那一天的权重理应比昨天大得多。EMA 写死了规则,应付不了这种"跳跃"。
因果卷积同样是上面那个公式,只是不用人脑去拍板衰减曲线,而是把权重 \(w_i\) 交给神经网络,让它在反向传播中自己学出来。
为什么要强调"因果"?¶
因果卷积里的"因果"二字,是为了防一个回测中最常见的问题——未来函数(Data Leakage)。
普通 CNN 在图像处理里很成功,因为识别图片时看全局信息没问题。
但如果把标准卷积直接套在 K 线上,就会把 \(t+1\)、\(t+2\) 的数据也卷进去,相当于在做今天决策时提前看到了明天的收盘价。
当模型使用普通卷积核计算今天(\(t\) 时刻)的特征时,滑动窗口会不可避免地把明天(\(t+1\))甚至后天的数据也卷进去。
这就相当于在做今天的交易决策时,模型已经提前“看”到了明天的收盘价。
用这种结构训练出的模型,在回测时往往能跑出惊人的夏普比率,但一上实盘就会迅速崩溃。
正如 Marcos Lopez de Prado 所说:“在金融领域,最难的问题从来不是预测,而是验证你有没有作弊。”
为了在网络结构上彻底杜绝这种“作弊”,我们需要引入“因果”的限制。
所谓因果卷积(Causal Convolution),其核心原则非常明确:今天的输出,只能依赖今天及以前的历史输入,绝对不能越界。
在标准的卷积公式 \(y_t = \sum_{i=-k}^{k} w_i \cdot x_{t-i}\) 中,\(i\) 为负数时代表提取了未来的数据。因果卷积强行将公式修改为: $$ y_t = \sum_{i=0}^{k-1} w_i \cdot x_{t-i} $$ 彻底切断了 \(x_{t+1}, x_{t+2}\) 等未来信息的流入。
1 2 3 4 5 6 7 8 9 | |
在代码实现上,这其实只是一层窗户纸。在 PyTorch 中,我们只需要在序列的左侧(过去)进行 Padding 填充,而在算完之后,把右侧多出来的部分裁掉:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | |
感受野太小怎么办?¶
但只看最近几天是不够的,这就引出了 感受野(Receptive Field) 的问题。
如果卷积核大小是 3,它就只能看到前 3 根 K 线。要看清过去一年的宏观趋势,难道要堆叠上百层网络吗?
那不仅会耗尽算力,还会导致梯度消失(简单来说,就是模型太深了,像传话游戏一样,传到最后信息全丢了,模型啥也学不到)。
为了解决这个问题,研究人员引入了 膨胀(Dilation) 操作。
简单来说,就是让卷积核学会“跳着读”数据。
数学上,带有膨胀系数 \(d\) 的因果卷积可以表示为: $$ y_t = \sum_{i=0}^{k-1} w_i \cdot x_{t - d \cdot i} $$
- 当 \(d=1\) 时,模型老老实实看连续的几天:今天、昨天、前天。
- 当 \(d=2\) 时,模型隔天读取:今天、前天、大前天。
- 随着层数的加深,膨胀系数呈指数级放大(如 \(d=1, 2, 4, 8 \dots\)),模型开始抽取周级别、月级别的特征。
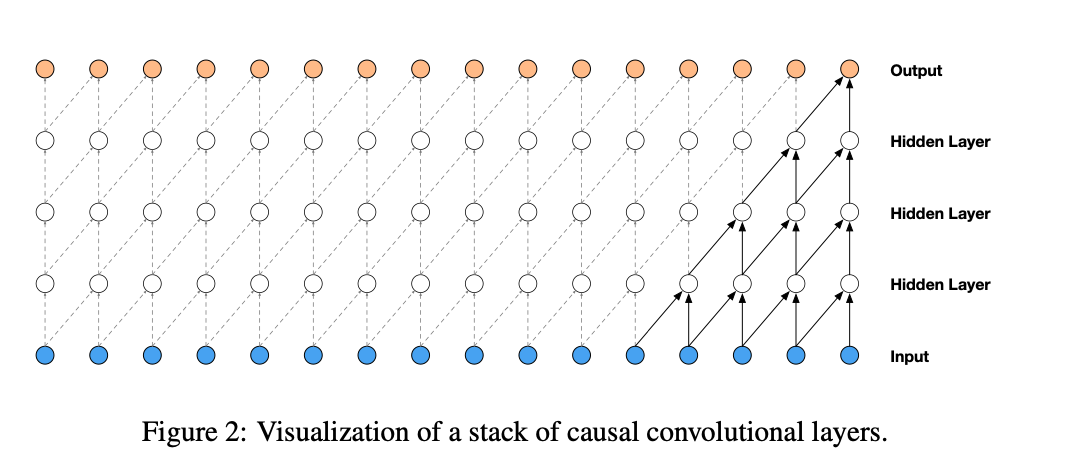
这就好比一个老练的交易员,他不仅会盯着 5 分钟线的微观博弈,也会时不时切到日线和周线去看宏观趋势。
不同膨胀率的因果卷积层叠加在一起,就构成了经典的 TCN(时间卷积网络)。它巧妙地用极少的计算资源,实现了多周期共振的看盘逻辑。
并非稳赚不赔¶
在把因果卷积当作万能钥匙之前,我们必须清醒地认识到:它依然是一个基于历史数据的归纳工具。
如果你的原始数据本身就是一堆信噪比极低、毫无规律的随机漫步,哪怕 TCN 把感受野开得再大,提取出来的也只是一堆浓缩的噪音。
它不可能无中生有地给你变出 Alpha。
但不可否认,它为我们提供了一个极其趁手的工具。可以将一段时期的量价走势,安全地(无未来函数)压缩成一个特征向量。
无论是将这个向量输入全连接层进行收益率预测,还是将其作为强化学习算法中的环境状态(State),它都展现出了极高的工程价值和计算效率。
这篇文章是我们《因子分析与机器学习策略》中的内容,出现在如何处理时序特征那一部分。对因果卷积得到的一些重要结果,将成为我们在深度学习策略中用以训练的核心特征。更多关于如何驾驭这些模型的探讨,我们课堂上见!
💡 最后补充一句: 在实盘应用 TCN 时,最大的坑往往不在网络结构,而在数据的预处理。直接将未经平稳性处理或横截面标准化的绝对价格喂给网络,模型大概率会陷入迷茫。
正如文艺复兴科技创始人 Jim Simons 所说: "In this business it's easy to confuse luck with brains." (在这个行当里,人们总是太容易把运气当成自己的才华)。当你用高级的因果卷积赚了钱时,不要以为是模型有什么神奇魔力,那可能只是刚好拟合了当下的市场情绪。在量化领域,永远要对市场的混沌保持敬畏。