Kaggle 表格赛里,XGBoost 为什么总有竞争力?
最后更新: 2026-04-03
Table of Content
Kaggle 表格赛里,XGBoost 为什么总有竞争力?¶
Kaggle 的表格赛里,能把 leaderboard 分数做上去的模型不少,但真到后半程,常留在桌上的,还是 XGBoost 这类树模型。
很多人会把原因归到一句俗话上:表格数据适合树。这句话没错,但还不够。
如果把这件事讲得更本质一点,XGBoost 的强,不只是它会拟合,而是它每一步都在问:
这一步更新,值不值?
XGBoost 更关键的一点是:它每补一棵树,都先做两步判断。
- 这批样本该怎么修
- 修到这里以后,还要不要继续拆
整篇文章其实只讲这一条线:先看一次更新怎么定,再看它怎么落成叶子值,最后看分裂为什么能用 gain 来判断。
Kaggle 的表格赛,放到量化里其实就是因子表¶
如果把 Kaggle 里最典型的 tabular 比赛翻成量化语言,其实很像横截面因子表。
每一行是一只股票,每一列是一个特征,目标可能是下周收益、超额收益,或者某种风险状态。
先盯住一类样本就够了:低估值、低波动的股票。假设模型老是把它们的下周收益预测得偏低。
后面只要盯住这批股票就够了:
- 既然老被低估,这一轮该怎么往回修
- 修完这一轮以后,要不要再按别的条件拆开
先别看树,先看误差是怎么动的¶
这一节先不管树,只看第一个麻烦:既然“低估值 + 低波动”这类股票老被低估,模型第一步到底该怎么修?
如果预测目标是“下周收益”,那当前预测 \(\hat y\) 改成 \(\hat y + \Delta\) 以后,损失会怎么变。
训练每次更新,本质上只回答两件事:该往哪边修,以及这一步该修多大。
一阶信息给方向:往哪边改,损失会更低。二阶信息给幅度:方向对了以后,别一下修过头。
用最短的泰勒展开,把这件事钉住¶
要把上面这一步算清楚,最短的写法就是在当前点附近看一小步 \(\Delta\) 会让损失怎么变:
这里的 \(g\) 是一阶导数,\(h\) 是二阶导数。只看这个式子就够了:\(g\Delta\) 决定方向,\(\frac{1}{2} h \Delta^2\) 限制步子别太大。
把它再往下推一步,最低点就在
这个式子已经把核心说完了:\(g\) 决定往哪边修,\(h\) 决定敢修多大。\(h\) 越大,更新就该越保守。
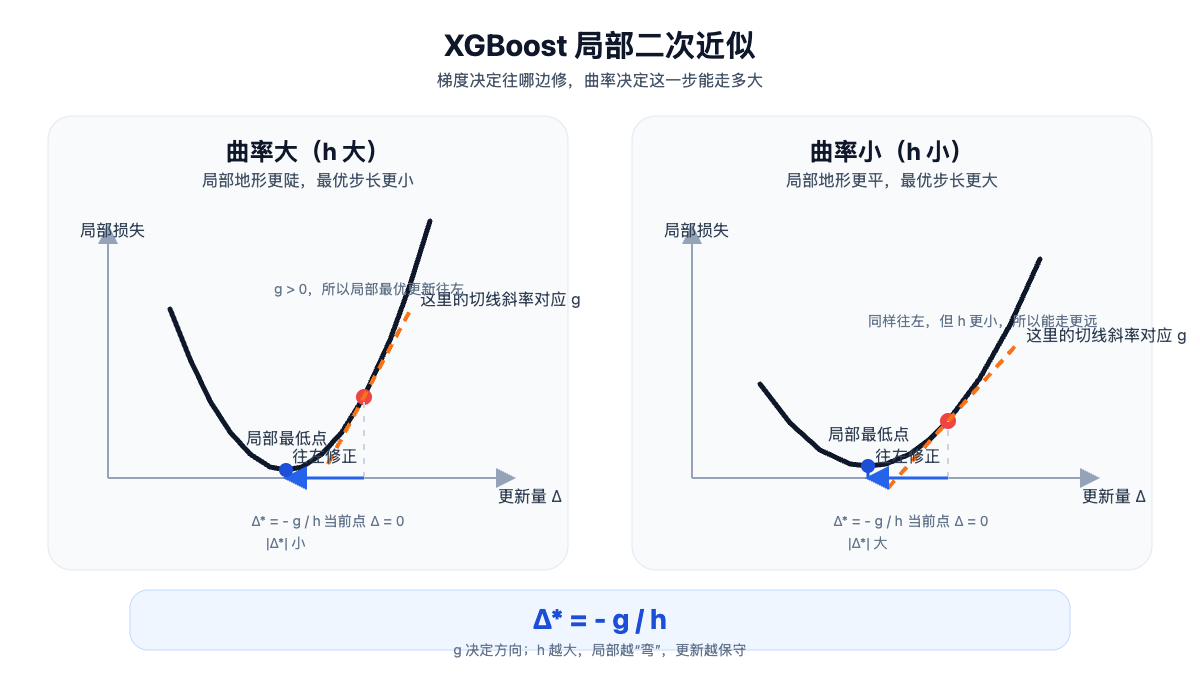
- 黑色曲线:当前点附近的局部损失形状。
- 橙色虚线:红点处的切线,对应一阶导数,只负责告诉你哪边是下坡。
- 蓝色箭头:这一轮真正采用的更新量,从 \(\Delta=0\) 走到 \(\Delta^*=-g/h\)。
- 左图更弯,\(h\) 更大,所以步长更小;右图更平,所以步长可以更大。
但问题还没结束。上面的 \(\Delta\) 像是在给单个样本单独修正,可树模型不能给每只股票都配一个参数。XGBoost 的做法是先按条件把样本分组,再让同一叶子的样本共用一个值。
回到 XGBoost,它为什么非要把这件事算进去¶
回到 XGBoost 的训练过程,这件事就会落到树上。它不是一口气长成一棵大树,而是一轮一轮往现有模型上补小树。
前面那个“这批股票该修多少”的问题,到了这里会变成:新加的这棵树,应该让哪些样本拿到同样的修正。
第 \(t\) 轮时,模型已经有了当前预测 \(\hat y_i^{(t-1)}\),现在它准备再加一棵树 \(f_t(x_i)\),于是新预测变成:
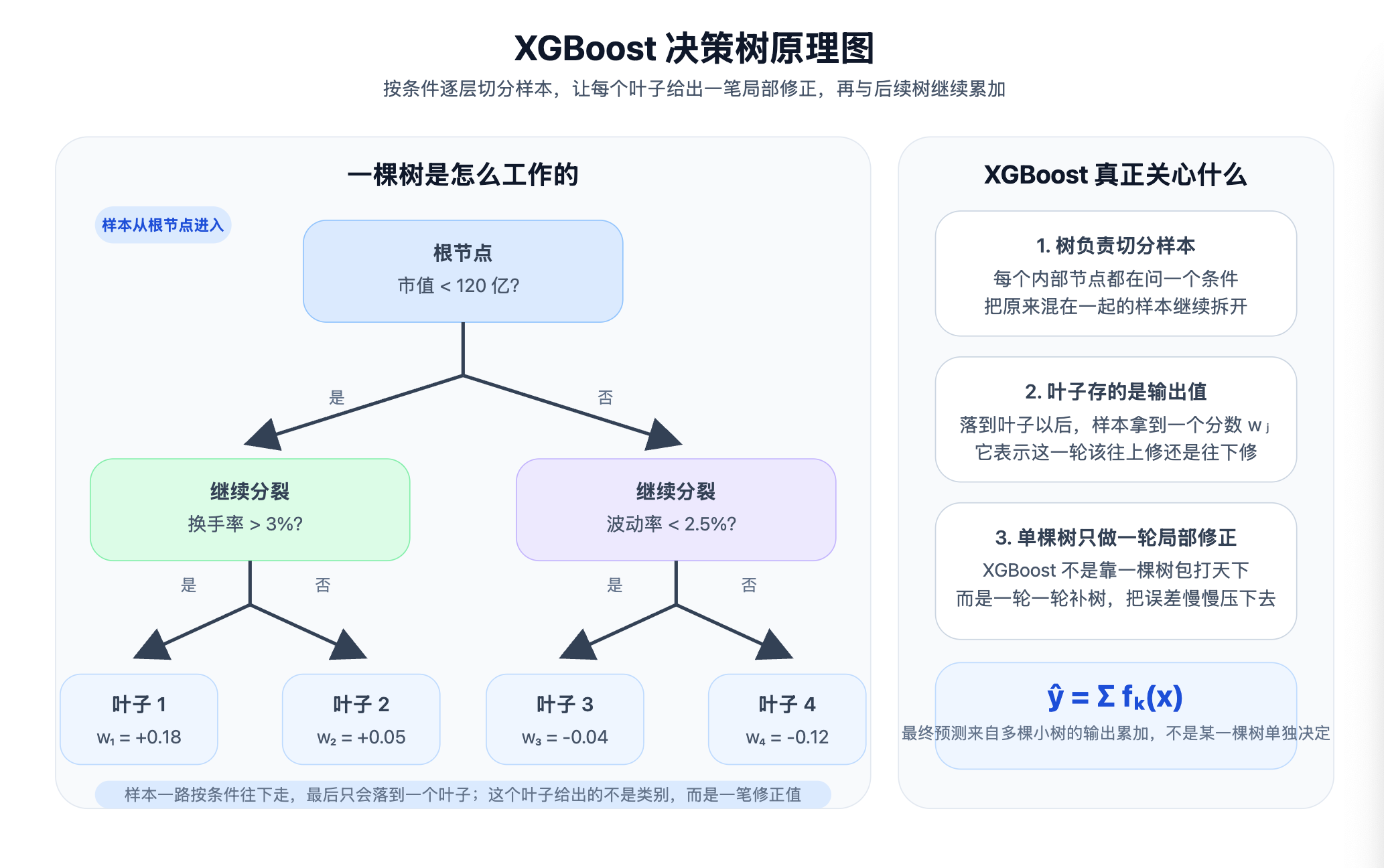
- 分裂节点:样本按条件往下走,不同条件对应不同分支。
- 叶子节点:样本最后落到一个叶子里,拿到一个输出值 \(w_j\)。这个值表示这一轮要修多少。
- 最下面那行 \(\hat y = \sum f_k(x)\):最终预测来自多棵树的输出累加,不是一棵树单独决定。
这张图放在这里,只是为了把前面的局部修正接到树结构上:前面算的是“该修多少”,到了树里就变成“哪些样本分到一组,一起修多少”。
真正的问题不是“我能不能再长一棵树”,而是:这棵树加进去以后,损失到底会下降多少。
原始损失函数通常不好直接和树结构一起处理,所以 XGBoost 就在当前预测点附近做二阶泰勒展开:
这一步做完以后,“加一棵树后损失怎么变”就被改写成了一个局部二次目标。
接下来的想法很直接:既然不能给每只股票单独放一个 \(\Delta\),那就先把表现相近的样本分到同一个叶子里,再给这整组样本一个统一修正。
如果前面那批“低估值 + 低波动”的股票被分到同一个叶子里,模型就不会一只一只地修,而是直接给这一组一个共同的值。
如果第 \(j\) 个叶子的样本集合是 \(I_j\),记
那么这个叶子的最优输出就是:
这条式子可以直接读成三部分:
- \(G_j\) 决定修正方向
- \(H_j\) 限制修正幅度
- \(\lambda\) 用来压住过大的叶子输出
到这里,\(\Delta\) 就落成了叶子值:前面讲单个样本怎么修,到了树模型里,就变成这一组样本一起修多少。
分裂 gain 为什么也能算出来¶
但叶子值还不是最后一步。
现在这批“低估值 + 低波动”的股票,虽然已经能共用一个叶子值了,可它们内部也可能还不一样。比如再按“高换手 / 低换手”切一刀,也许会比放在一起修得更准。
所以叶子值回答的是“先不再分,统一给多少修正最合适”;gain 回答的是“如果再切一刀,值不值”。
也就是说,先算“放在一起怎么修”,再算“拆开以后能不能更准”。能,gain 就大;不能,就别分。
上面那套局部二次目标,刚好可以把这个“拆开以后多好了多少”算出来。所以 XGBoost 才会有那条经典的 gain 公式:
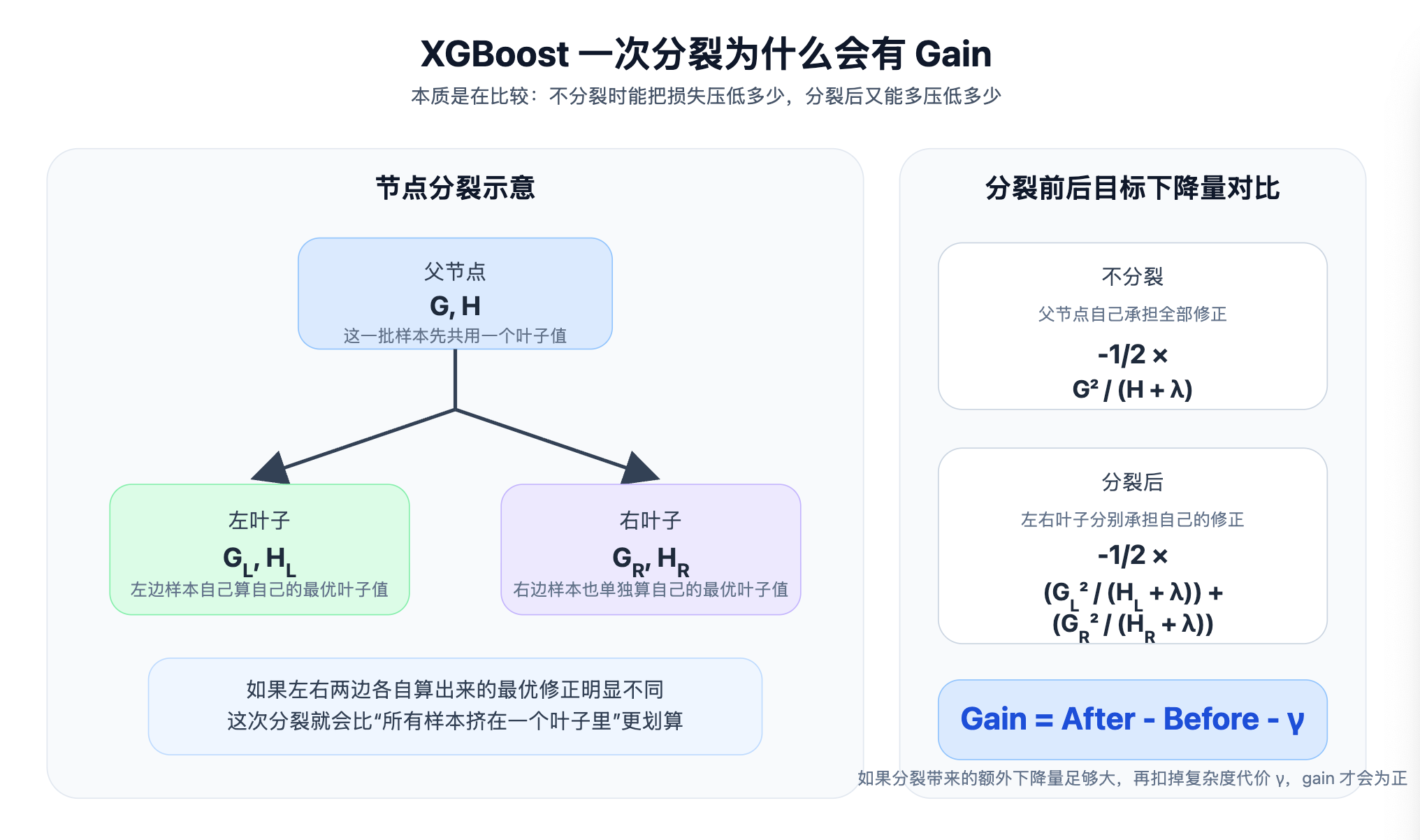
- 父节点的 \(G, H\):表示不分裂时,把这批样本放在一起算。
- 左右叶子的 \(G_L, H_L\) 和 \(G_R, H_R\):表示分裂后,左右两边分开算。
- 最下面的 gain:就是“分开算”比“放在一起算”多带来的那部分下降量,再减去复杂度代价 \(\gamma\)。
到这里,叶子值和 gain 的分工就清楚了:
- 叶子值回答:这一轮先怎么修
- gain 回答:修到这里,还要不要继续分
在代码里,参数到底在管什么¶
到了参数层面,核心也没变,还是在管同一件事:别让模型太轻易相信局部模式。翻成前面的主线,就是别修太猛,也别太容易继续往下分。
eta:控制每一轮修正的幅度lambda、alpha:压住过大的叶子输出min_child_weight、gamma:要求证据够多、收益够大,才允许继续分裂
再回到标题¶
很多 Kaggle 表格赛里,XGBoost 当然有树模型适合表格数据这层优势。但更关键的是,它不会把“继续拟合”当成理所当然。
它每补一棵树,都不是一味往下长,而是在衡量两件事:这一轮该修多少,以及还有没有必要继续分裂。前一个问题靠一阶、二阶和叶子值,后一个问题落在 gain 上。
放到量化里看,这一点尤其重要。真正危险的往往不是模型不够复杂,而是模型太容易把阶段性行情、极端样本和偶然条件当成稳定规律。XGBoost 用一阶、二阶和正则化把每一步都卡得更严,本质上是在尽量延后这种失控。
XGBoost 总有竞争力,不只是因为它会长树,而是因为它每补一步都会先判断:这批样本该怎么修,修到这里以后还要不要继续拆。