聊聊 TCN:一种更清晰的时间序列解构方式
最后更新: 2026-03-30
Table of Content
很多刚接触量化深度学习的朋友,第一反应往往是去跑 LSTM 或者 GRU。
我当年写毕业论文的时候也是这样。那时候觉得循环神经网络(RNN)简直是为金融序列量身定做的:它有“记忆”,能处理时间前后的逻辑。
我兴冲冲地把 A 股几年的量价数据喂给 LSTM,幻想着能跑出一个完美的预测曲线。
但现实打脸很快。
不管我怎么调参数、加层数,LSTM 预测出来的结果总像是在“追涨杀跌”——它其实只是在平移昨天的价格,一旦遇到行情突变,模型就彻底崩了。
当时我的导师跟我说:“你要不试试 TCN(时间卷积网络)?”
说实话,我当时挺抵触的。卷积网络(CNN)不是用来做图像识别的吗?
拿来看 K 线是不是有点不务正业?而且我试了之后,TCN 在那份论文数据上的表现其实也只能说差强人意,并没有那种“降维打击”的神奇。
但就在那个不断撞南墙的过程中,我开始意识到,TCN 真正有价值的地方,并不在于它能把准确率提高几个点,而在于它用一种极其清晰、极其“量化”的逻辑,重新解构了时间序列。
在量化建模里,我们本质上都在解决一个问题:怎么给历史数据分配权重。
在上一篇文章里,我们聊过因果卷积如何取代 MA/EMA,让模型自己去学权重: $$ y_t = \sum_{i=0}^{k-1} w_i \cdot x_{t-i} $$
如果说因果卷积解决了 “怎么给历史分配权重”的问题,那 TCN(Temporal Convolutional Network)解决的就是“如何构建一个多尺度的特征金字塔”。
但如果你已经接受了因果卷积这件事,一个问题很快就会冒出来:既然卷积核已经可以自己学权重,为什么还需要 TCN?
因为因果卷积只解决了“怎么给近处的历史分配权重”,还没有解决“怎么把更远的历史安全地纳入进来”。
假设卷积核大小 \(k=3\),那它一次最多也就看 3 个时间步。对于短线波动,这当然够用;但如果你想同时判断日内噪音、周级动量和月度趋势,3 个点的视野显然太窄了。你可以暴力地把网络堆深,但层数一多,训练马上就会变得不稳定。
所以 TCN 的第一步,不是发明一种全新的网络,而是在因果卷积的基础上,把“看得远”这件事做得更干净。
在上一篇文章中,我们已经讲过膨胀卷积(Dilated Convolution)。它把普通因果卷积 $$ y_t = \sum_{i=0}^{k-1} w_i \cdot x_{t-i} $$
改写成 $$ y_t = \sum_{i=0}^{k-1} w_i \cdot x_{t-d\cdot i} $$
也就是在时间轴上按步长 \(d\) 去取样。
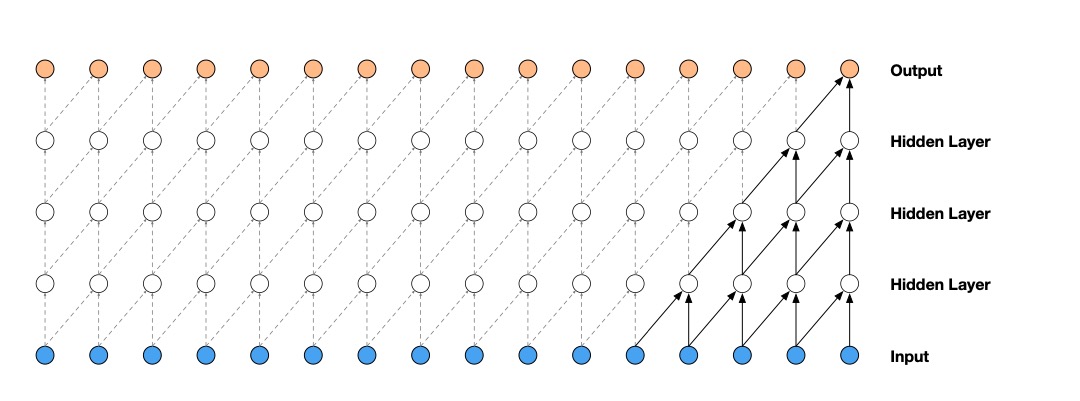
当 \(d=1\) 时,它和普通因果卷积没有区别;当 \(d=2,4,8\) 逐层放大时,感受野就会指数级扩张。如果把每一层理解成一次卷积操作,一个常见的结果是: $$ RF = 1 + (k-1)(2^L - 1) $$
这意味着你不需要把网络堆到很夸张的深度,就能把几天、几周、甚至几个月的历史同时纳入视野。
而在 TCN 论文常见的残差块实现里,每个 block 往往会串两层膨胀卷积,所以实际感受野通常还会比这个式子再大一截。
这才是 TCN 真正有价值的地方:它不是简单把历史拉长,而是把不同时间尺度上的信息放到同一个卷积框架里处理。
TCN 的每一层其实都在处理不同尺度的信息: * 底层(\(d=1, 2\)):在捕捉高频的波动和盘口的跳跃(短线微操)。 * 中层(\(d=4, 8\)):在提取周级别的动量或回归(中线博弈)。 * 高层(\(d=16, 32\)):在审视数月之久的趋势或季节性(长线格局)。
通过多层膨胀卷积的叠加,TCN 能够同时在底层保留对分钟级波动的敏感度,并在高层捕捉周线甚至月线级别的趋势。
这种“指数级扩张”的视野,让 TCN 能够用极浅的层数覆盖超长的历史跨度,从而避开了 LSTM 这种深层循环网络中常见的梯度弥散问题。
深度稳健:如何让深层网络在噪音中“活下去”?¶
有了膨胀卷积,我们就能“看”得很远,但随之而来的问题是:网络变深了。
在图像处理中,深层网络是王道;但在量化领域,深层网络往往是灾难。
金融数据的信噪比极低,且具有严重的非平稳性。如果只是简单地堆叠卷积层,模型很快就会在梯度的消失或爆炸中迷失,或者干脆陷入过拟合的泥潭。
TCN 真正的精髓,在于它通过一套 残差块(Residual Block) 结构,在“深度”与“稳健”之间找到了一个极佳的平衡点。
残差块:从“预测价格”到“预测偏差”¶
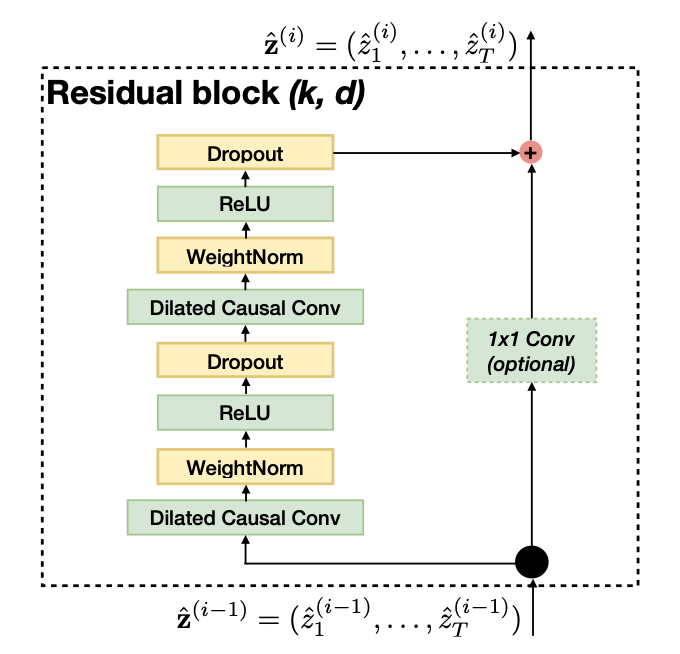
所以 TCN 的第二步,是给深层网络加一条“别把事情做坏”的约束。这就是残差块。它把每一层的输出写成 $$ \mathbf{y} = \sigma(\mathbf{x} + \mathcal{F}(\mathbf{x})) $$
其中 \(\mathbf{x}\) 是原始输入,\(\mathcal{F}(\mathbf{x})\) 是卷积层学出来的修正量。
很多介绍 ResNet 的文章都会说,残差块的作用是“缓解梯度消失”。这话没错,但放在时序建模里还是太轻了。
更准确地说,残差块是在改变问题本身。原来网络要直接学习一个完整映射 \(H(\mathbf{x})\);现在它改成只学习: $$ \mathcal{F}(\mathbf{x}) = H(\mathbf{x}) - \mathbf{x} $$
也就是在原始输入基础上的偏差。
这个改写在量化里尤其重要。因为价格序列有很强的自相关性,预测下一时刻时,当前价格本身就是最自然的基准。
残差结构等于是在告诉模型:你不用每次都从零开始重建整条价格曲线,你只需要回答一个更现实的问题——在当前基准上,是否存在一个值得修正的偏差。
从优化角度看,这个结构还有一个更硬的好处。反向传播时,梯度对输入的导数会变成 $$ \frac{\partial \mathbf{y}}{\partial \mathbf{x}} = I + \frac{\partial \mathcal{F}}{\partial \mathbf{x}} $$
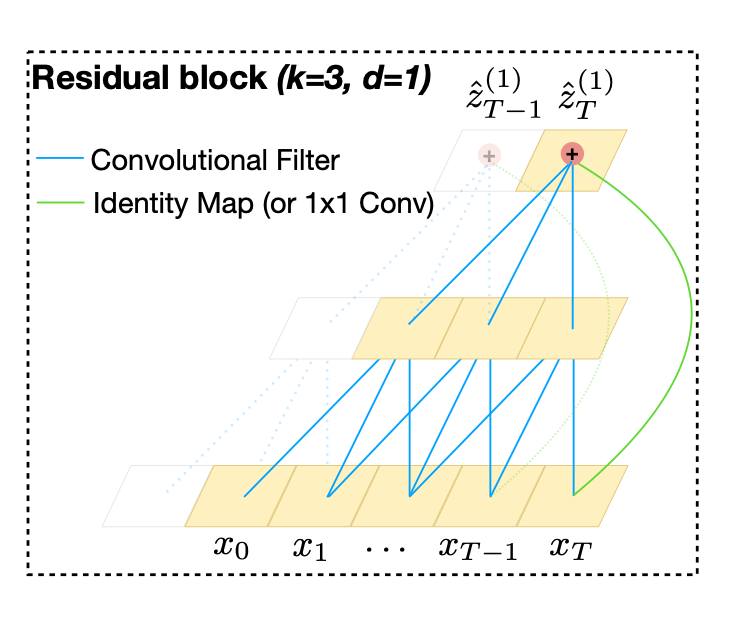
这里那个恒等映射里的 \(I\) 很关键。它意味着哪怕卷积分支一开始什么都没学到,梯度依然有一条近乎直通的路可以往回传。
对深层 TCN 来说,这比“多学到一点特征”更重要,因为金融序列最怕的不是模型不够复杂,而是网络一深,先把最原始、最稳定的价格结构给扭坏了。
如果某一层没有提取到有效 Alpha,最好的做法不是硬学一个复杂变换,而是让 \(\mathcal{F}(\mathbf{x})\) 尽量靠近 0,把信号原样放过去。
也正因为如此,残差块给深层 TCN 留出了“自我退化”的空间:学不到 Alpha 时,至少别破坏原来的价格结构。
但残差还不够。深层网络要稳定训练,还得解决优化路径本身的问题。
这里很多教程会顺手上 Batch Norm,但在时序任务里它并不讨喜。Batch Norm 的做法是把激活值标准化成 $$ \hat{x} = \frac{x - \mu_B}{\sqrt{\sigma_B^2 + \epsilon}} $$
其中 \(\mu_B\) 和 \(\sigma_B^2\) 来自一个 batch 内的统计量。
这件事放在图像上往往没问题,因为图片之间默认可以共享统计结构;但放在金融时序里就很危险。
今天的震荡市、明天的单边市、下周的突发利空,本来就不是同一种分布。
你把这些时间片揉在一个 batch 里求均值和方差,本质上是在强行假设它们共享同一个“正常状态”。最后得到的,常常不是更稳定的特征,而是一个被平均掉、被抹平了 regime 差异的特征。
TCN 更常用的是权重归一化(Weight Normalization)。它不去碰激活值,而是直接对权重做重参数化: $$ \mathbf{w} = g \frac{\mathbf{v}}{|\mathbf{v}|} $$
把权重的大小和方向拆开处理。这样做的好处,不是写法更漂亮,而是优化时更稳。
梯度更新时,不必同时纠缠“往哪儿走”和“走多大步”这两件事,深层网络更容易收敛。更关键的是,它没有把不同时间片的统计量搅在一起,因而更适合这种分布随时会漂移的序列。
最后是 Dropout。很多人把它当成一句“防过拟合”带过去,但放在 TCN 里,它其实承担的是很具体的工程作用。训练时它会对特征施加一个 Bernoulli 掩码: $$ \tilde{\mathbf{h}} = \mathbf{m} \odot \mathbf{h}, \quad m_i \sim \text{Bernoulli}(1-p) $$
也就是说,每一次前向传播,都会有一部分通路被临时切断。
这在金融建模里特别重要:因为金融数据里偶然噪音太多,如果某一层恰好抓住了一段只在样本内成立的量价组合,网络很容易把它当成真规律记下来。
Dropout 做的事,就是逼着模型不要依赖单一路径,而是去寻找在不同样本里都能重复出现的结构。
你也可以把它理解成一种非常粗暴的模型集成:每次训练都在不同的子网络上进行,最后能稳定保留下来的,往往不是最花哨的信号,而是最不容易失真的那一类信号。
说白了,TCN 不是比因果卷积“更高级”一点而已。它是在因果卷积的基础上,继续把两个问题补齐了:一个是怎么把更远的历史纳入进来,一个是网络变深以后怎么别把信号学坏。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | |
回头看,TCN 真正打动我的地方,并不是它比 LSTM 多新潮,也不是它在某个数据集上多赢几个点,而是它把时间序列建模里几个最麻烦的问题拆得很清楚:
先守住因果,再扩大视野,最后保证深度不会把原始信号毁掉。
这也是为什么我后来越来越把它当成一个特征提取框架,而不是一个包治百病的预测神器。
它做不到凭空变出 Alpha,但它至少提供了一种足够干净、足够稳定的方式,帮我们把混乱的历史序列整理成还能往下研究的东西。