Kronos
最后更新: 2026-01-12
Table of Content
- slidev_themes/addons/slidev-addon-quantide-layout
- slidev_themes/addons/slidev-addon-mouse-trail-pen
- slidev_themes/addons/slidev-addon-array
- slidev_themes/addons/slidev-addon-interactive-table
- slidev_themes/addons/slidev-addon-card aspectRatio: 3/4 layout: cover-random-img-portrait
困局:通用时序模型为何在金融市场“水土不服”?¶
这几年,我们见证了 GPT 等大语言模型(LLM)如何通过“阅读”海量文本,学会了人类的语言、逻辑甚至创造力。以GPT为代表的大模型范式取得了巨大成功,进而也启发了像TimeGPT等时间序列基础模型的发展。在这一快速发展的研究领域中,金融市场成为时间序列基础模型极具挑战性的关键应用场景。之所以说它极具挑战性,核心症结在于 “模型训练基础” 与 “金融数据特性” 的双重不匹配。
一方面,现有通用时间序列基础模型的预训练语料库以电力负载、交通流量、太阳能发电等物理场景数据为主,金融序列在其预训练语料中占比极低。通用模型通过电力、交通等数据,它学到的是 “电力白天高、晚上低” 的日内周期、交通 “早晚高峰” 的双峰模式等物理驱动的稳定规律。这些规律具备极强的平稳性和可预测性。但K线序列却具有独特的低信噪比、强非平稳性。这些特性与通用时间序列基础模型的 归纳偏好严重不符,最终不仅使其在金融任务中的性能往往不及简单线性模型,更无法在广泛的量化金融场景中实现有效泛化。

另一方面,K 线是一种基于蜡烛图的多元时间序列,它记录了固定时间间隔内的开盘价、最高价、最低价、收盘价以及成交量和成交额这六维数据。这些序列构成了一种高度紧凑、信息密集的 “语言”,市场参与者通过它去解读价格的波动、波动率的状态、流动性的变化以及集体情绪的转变。
然而,对于一个多变量的时间序列模型,无论是像自回归积分移动平均这种经典的计量经济学模型,还是LSTM等机器学习模型,亦或是TimePGT等已有的通用时间序列基础模型,它们处理数据的方式本质上仍是数值计算。在这些模型的“视角”里,开盘价等 6 维数据虽然被同时输入,但它们仅仅被视为一组多维浮点向量,模型缺乏将这六个维度作为一个‘语义整体(K线形态)’来认知的机制。这种将 K 线拆解为纯数字的底层逻辑,往往导致模型难以捕捉诸如‘长下影线’等具有强金融含义的结构化特征。
因此,为了解决这些不足,清华大学李健团队在今年8月推出了 Kronos,这是一款基于仅解码器的transformer架构,专为金融 K 线数据打造的统一、可扩展预训练框架。kronos宇宙首次将 K 线数据视作具备逻辑的 “市场语言”,在这里,K 线及 K 线组合不再是孤立的数字序列,它们成为了承载市场运行状态、资金意图与趋势方向的表达载体,具备语义、语法与上下文依赖关系。
在深入了解 Kronos 的工作流程之前,我们不妨先聊聊它的命名。这个名字背后藏着研究团队的巧思与雄心。在希腊神话中,Kronos 是掌管时间的神明,象征着从混沌中梳理秩序、掌控时间流转的力量;而研究团队用 “Kronos” 命名,正是想借这层寓意,揭示模型的核心目标是要成为能理解金融时间序列混沌波动、并从中提炼规律的 “时间驾驭者”。

深度解读:Kronos 如何赋予 K 线“语义”?¶
Kronos的工作架构非常清晰明了,主要分为 “分词器” 和 “自回归模型” 两大核心部分,分别是下图的左右两张图。我们先聚焦第一部分——分词器。这一阶段的目标是将连续的 K 线数据,转化为机器可理解的 “金融语义单元(Token)”。
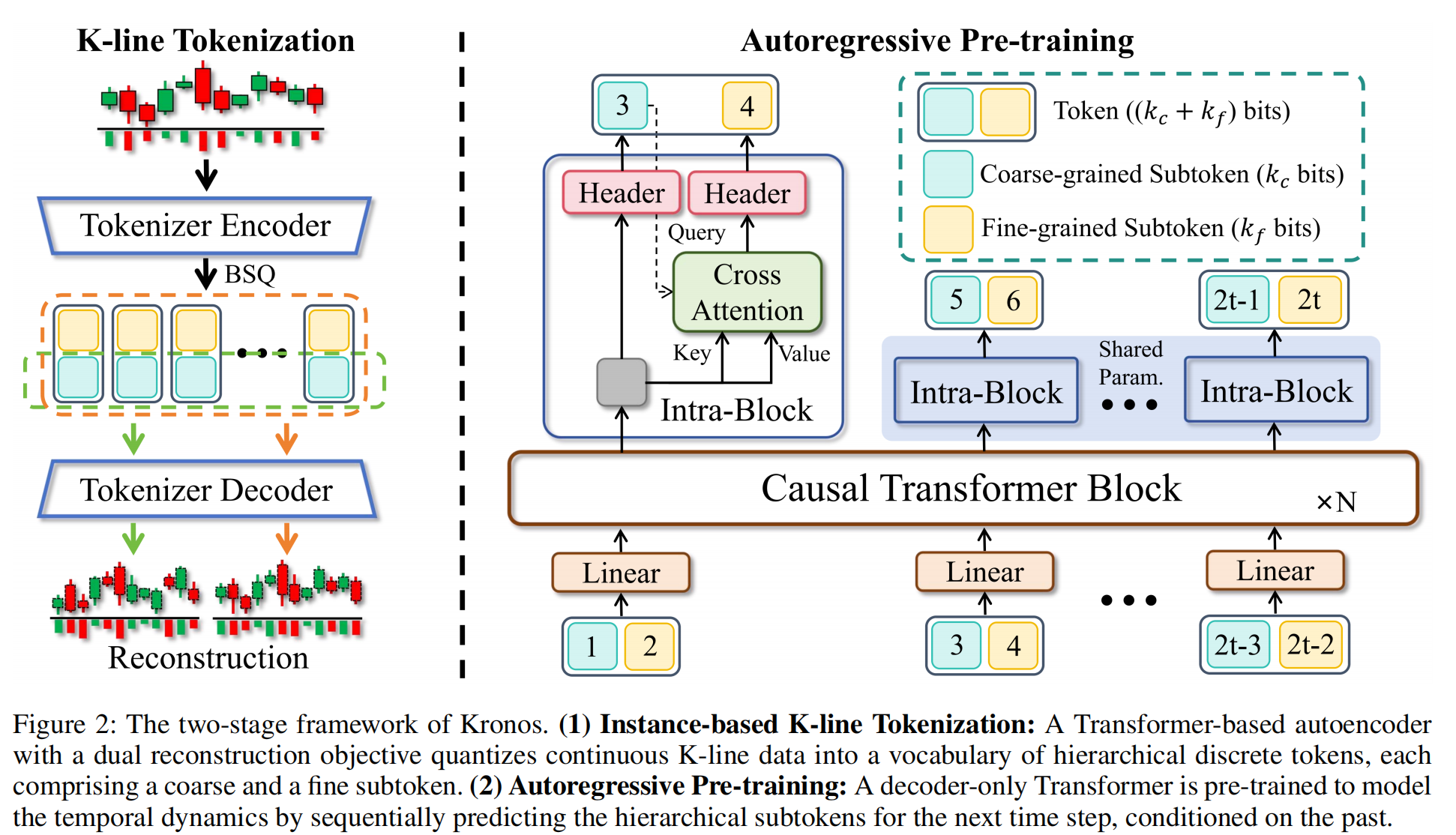
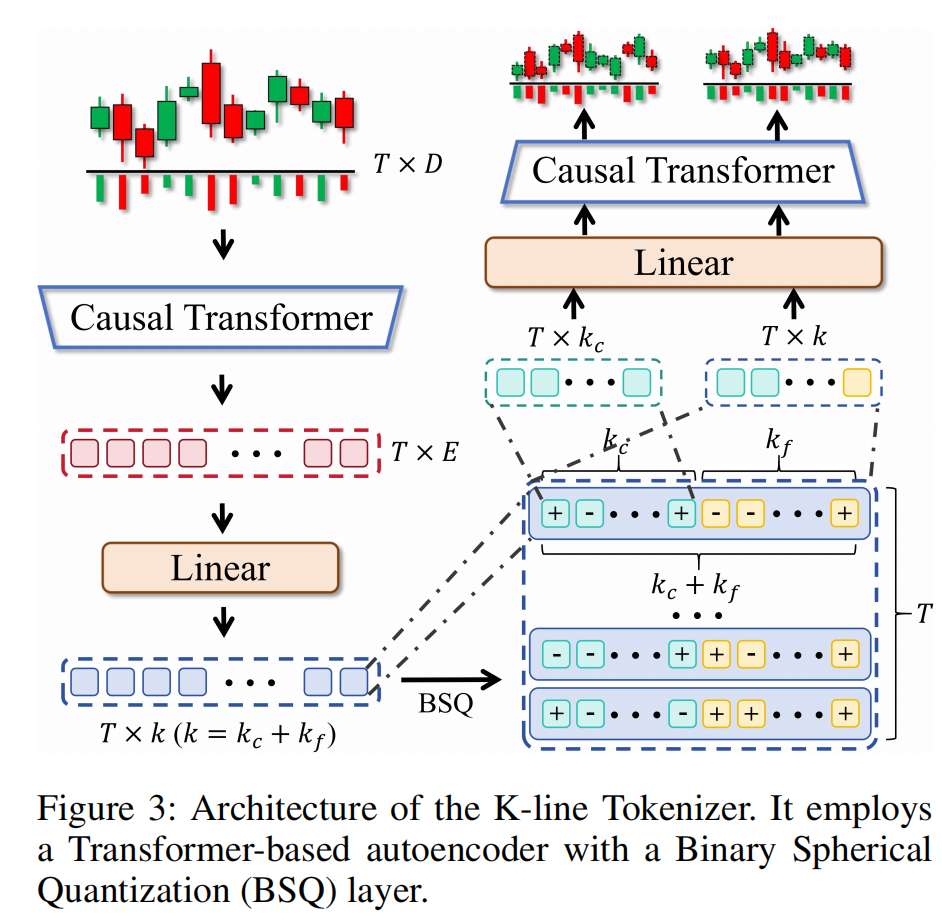
在 NLP 领域,token 是语言的最小单元,而在 Kronos 的体系中,金融市场语言的最小单位是 “语义单元”,这个单元由单根或多根 K 线共同构成。但原始 K 线包含开盘价、最高价等六维连续数据,没法直接成为承载语义的 “市场语言单元”,所以研究团队专门设计了针对 K 线的分词器(Tokenizer)。
它先将原始的 K 线序列(图上方的红绿 K 线)送入 “Tokenizer Encoder”,通过 BSQ(二进制球面量化)技术,把开盘价、成交量等六维连续数据,量化成分层的离散 Token。为了同时捕捉市场的 “宏观趋势” 与 “微观细节”,Kronos 采用分层 Token 设计,将每个 Token 拆分为粗粒度子 Token、细粒度子 Token两个部分。
其中,粗粒度子 Token是对原始连续 K 线数据的低保真重构表示,负责捕捉 “价格趋势、成交量量级” 等宏观特征;细粒度子 Token是对粗粒度表示的残差或细节修饰,负责捕捉市场的微观结构、具体幅度的精确值以及高频波动细节。简单来说就是粗粒负责看大势,细粒负责看细节。
量化后的 Token 会再经过 “Tokenizer Decoder” 重建出 K 线序列(图下方的 Reconstruction),确保 Token 既完成了离散化,又保留了原始 K 线的核心信息。
这里有一个极具技术深度的亮点。金融数据是连续型数据,理论上可取无限多个值,形成 “无限状态空间”。传统离散化常用等距分段或固定区间,不仅会把 100.1 和 100.2 这种 “语义相似但数值略差” 的情况强行拆分,还会因状态无限导致模型参数无法承载 ,进而导致计算复杂度高、泛化能力失效” 的问题。
因此,Kronos 引入了二元球面量化(BSQ)技术。它将高维向量投影到超球面上,寻找相似的投影。这意味着,即便价格数值有微小波动,只要形态和方向相似,它们就会被编码为同一个 Token。这个过程就像我们在自然语言中把“高兴”“喜悦”视为 “同义词”。这也是 Kronos 具有抗噪能力的来源。通过这个精妙的分词器,Kronos成功为金融市场编写了一本专属的《K线词典》。
拥有了专属的‘金融单词’Token之后,下一步就是让模型学会‘阅读’——自回归预训练(Autoregressive Pre-training)。这一阶段的目标是让模型学习 “市场语言 Token 的序列逻辑”。Kronos 采用了与 GPT 一脉相承的自回归预训练目标,得益于这种 Decoder-only(仅解码器) 的架构设计,Kronos 天生就具备了生成能力。它能根据过去的一系列“金融词汇”,来预测出下一个最可能出现的“金融词汇”。
在 Kronos 进行预训练或预测时,自回归模型严格遵循顺序依赖关系: 第一步:先基于历史 Token 的信息,预测下一个 Token 的粗粒度子 Token(k_c位)(比如图中 Header 输出的 “3”);
第二步:再通过 “交叉注意力(Cross Attention)” 结合已预测的粗粒度信息,进一步预测对应的细粒度子 Token(k_f 位)(比如 Header 输出的 “4”)。
为了训练这个大脑,研究团队喂给它来自XSHG(上海证券交易所)、XNAS(纳斯达克)、XJPX(东京证券交易所)、加密货币(Crypto)、外汇(Forex)等全球 45 个交易所、超过 120 亿条 K 线记录的庞大语料库。在这个过程中,Kronos 学会了金融市场的‘通用语法’,掌握了跨资产、跨地域的普遍涨跌规律。
论文中的实测数据极具说服力地验证了它的零样本迁移能力。当将在包含美股(XNAS)在内的全球45个交易所多市场语料上预训练的Kronos,直接应用于未见过的A股(XSHG)市场进行预测时,其预测准确度(RankIC)衰减幅度仅为5%-10%;作为对比,传统时序模型在相同跨市场零样本场景下,性能衰减达35%-45%。这种巨大差异的本质是因为传统模型依赖的是“数字的拟合”,仅学习特定市场的数值分布规律,而Kronos掌握的是跨市场通用的金融语义逻辑,这类由市场参与者行为逻辑决定的语义规律,在不同市场中具有一致性,因此泛化能力更强。
从回测到“平行宇宙”:Kronos 的实战想象力¶
刚才提到Kronos具有合成数据的能力,这个功能我们可以用起来。
传统回测最大的痛点是历史只有一次。一个策略在过去赚钱,究竟是因为逻辑过硬,还是仅仅运气好,赶上了适合它的那一段历史?我们无从知晓。现在,Kronos给了我们创造了一个实验室条件。你可以让它基于2020年1月的数据,生成1000种“没有发生但理论上可能发生”的后续走势。如果你的策略在真实历史里大赚,但在Kronos生成的1000个“平行宇宙”里有600个都亏得一塌糊涂,说明你的策略只是“运气好”,撞对了这段行情。反之,如果在90%的平行宇宙里都表现稳健,我们才能充满信心地说:这个策略的逻辑是真的过硬。 这,就是从“回测”到“压力测试”的质变。它可以解决量化策略的“幸存者偏差”问题。
此外,Kronos 的开源或许也为个人开发者和中小机构提供了一条‘小样本真数据 + 大规模合成数据’的高效路径。 我们仅需购买近期的真实高频数据作为‘种子’(Prompt)来确保逻辑的有效性,让Kronos 以此为基础,低成本生成无限量的变体数据。 这意味着,开发者无需采购昂贵的超长历史数据,仅凭少量的真数据作为引子,就能通过 Kronos 构建出涵盖各种极端行情和不同波动率的庞大训练集。这极大地降低了量化研究的数据门槛,让‘数据贫困’的个人开发者也能训练出泛化能力强的深度学习策略。
争议与反思:预训练模型是量化的终点吗?¶
质疑声音的关注点主要是围绕它是否具有实盘价值展开的:有人震惊于kronos样本外测试只用了 2024 年这一小段时间。他认为真正的量化策略至少要跨越牛熊、回测 5 到 10 年来验证稳健性,仅仅用 2024 年的数据无法证明策略在“熔断”、“股灾”或“大放水”等极端环境下的生存能力。也有人认为论文只谈 MSE(均方误差)、MAE(平均绝对误差),不谈回测收益率曲线这种论文纯粹是为了发文章而发,实盘肯定会亏损。
从实战的角度讲,他们的质疑是在理的。如果我们不承认这一点,就是盲目吹捧。
但是,站在 AI 研究的视角,在大语言模型的研究范式中,衡量标准通常是 Token 的预测准确率。对于高频/分钟级 K 线来说,一年的数据包含的 Token 数量可能有数百万级,在统计学上对于验证“模型是否收敛”是足够的。并且,Kronos 本质上是一个生成式模型,它的任务是‘复原市场’,而不是‘战胜市场’。 MAE 和 MSE 低,说明模型能很好地理解市场的波动规律,知道下一步大概率会在哪里震荡。但这并不意味着它能精准捕捉 Alpha。
这就好比,我们可以让 GPT 根据需求写出完美的 Python 代码,但如果你让 GPT-4 去预测哪只股票会涨,它也是瞎蒙。所以,直接裸用预训练模型做交易,亏钱是必然的,但这不代表模型没价值,只代表打开方式不对。
总的来说,Kronos 把K 线序列被重构为了充满语义的句子,把每一根 K 线变成一个承载信息的‘单词’Token,给我们在时序研究中确实带来新的思考角度。
本期问题¶
本期题图我们使用了某大学的一张照片。猜猜这是哪所大学?
