2026量化新基建(二) - sqlite 与 sqlite-utils
最后更新: 2025-12-31
Table of Content
很多人(包括我)对 sqlite 有一个错觉,第一,它是玩具;第二,它不能用于生产环境。
但实际上, sqlite 是一个非常优秀的数据库。在过去的 2025 年中,它与 postgres 一起名列数据库前二;并且一直是最多人使用的数据库。
量化人说量化事。sqlite 是一把精致的瑞士军刀,它小巧、灵活而强大,可以用在很多地方。但是,对量化人来说,有一个场景,非常适合使用 sqlite: 无须安装和设置、以 pythonic 的方式进行开发,并且具有非常好的性能。
这个场景,就是作为量化程序的交易数据库。
但是,一直以来,我是直接使用 python 内置的 sqlite3 模块来操作 sqlite 数据库的。直到最近,我发现了 sqlite-utils 这个库,它让我以最简洁的方式,获得了全所未有的表达力。
因此,我决定把 sqlite/sqlite-utils 作为 2026 年量化技术栈的第二篇推出。
性能银弹 - wal 模式¶
作为交易数据库,主要存储的数据是委托记录、成交记录、每日持仓和每日资资产表。这其中以委托记录的数据量为最大,因为我们需要把报单、撤单的记录也都保存下来。
根据量化新规的要求,每秒报单不超过 300 次,每日不超过 2 万次。这并不是一个很有压力的需求,sqlite 完全可以轻松应对。
比性能压力更重要的是,必须要支持并发读写。因为当一个委托被报单后,往往不会立即成交,而我们也不能为此委托一直等待。所以,成交状态一般是通过回调的方式来通知的。这些回调往往安排在其它线程中。
Question
可以在多个进程中,打开同一个 sqlite 数据库进行并发读写吗?
你可能得到的是这样的回答:
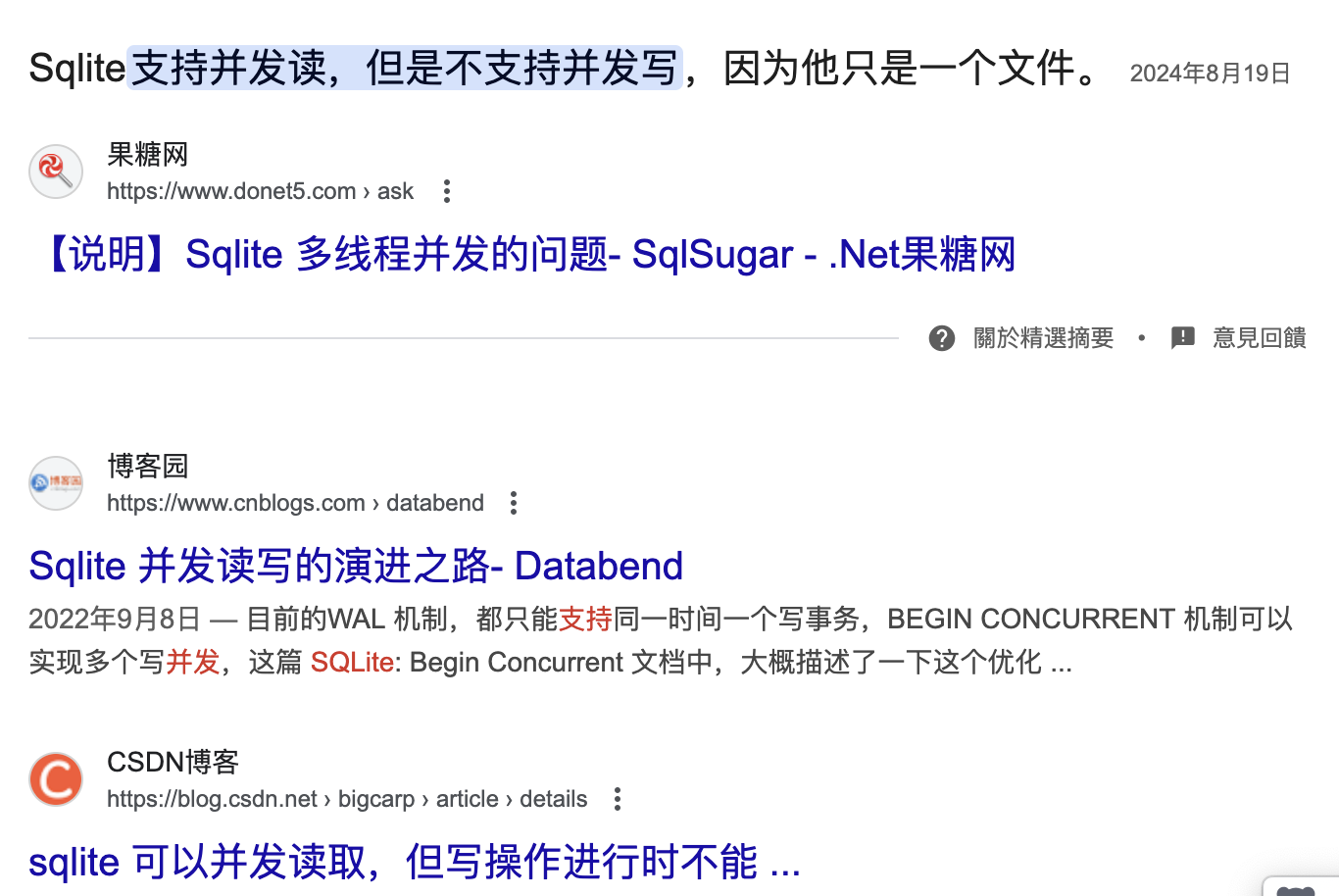
实际上,sqlite 从 2010 年起就支持多进程并发读写,并且用户不需要自己管理锁。但是,在 sqlite 中有两种模式,分别是"delete"和"wal"。而 sqlite 的默认选项一直是"delete"模式,这一模式不支持并发,这就导致了很多人就误以为 sqlite 无法支持并发读写。
根据测试和官方文档,启用 wal 模式实际上在几乎所有场景下,都能带来性能提升。但为何 sqlite 的默认选项一直是 delete 呢? 这是因为 sqlite 官方一直坚持这样一种文化 -- 他们一直希望 sqlite 是一个极简的、只有一个文件的数据库。而一旦进入 wal 模式,sqlite 将使用三个数据文件,他们担心部分用户可能会对此感到困惑。
在 wal 模式下,另外两个文件分别是。shm 和 .wal 文件。sqlite 把锁信息放在。shm 文件中 -- 这是一个共享内存文件;sqlite 在 wal 模式下,读数据时会从主库读稳定的数据版,无需加锁;而在写数据时,先会给。wal 文件加锁,只有在最终合并时,才需要短暂地给主数据库加上锁。
因此,在 wal 模式下,sqlite 的锁的粒度会比 delete 模式更细。所以,在 wal 模式下,即使是在单进程读写场景下,性能也会略好一点(5%左右)。
Tip
锁粒度的大小是许多并发场景下,数据库性能高低的关键。在高并发读写下,postgres 会比 sqlite 的性能强很多,是因为它的锁粒度基于 mvcc 技术,粒度要精细许多。
如果开启了 wal 模式,sqlite 处理单笔交易耗时可以远小于 0.1ms,这意味着,sqlite 可以处理每秒至少 1 万笔交易,因此,sqlite 是完全胜任交易数据库的。甚至,由于它不需要经过网络接口,它的延时可能比网络数据库更低。
要允许多个进程中同时读写同一个 sqlite 数据库,你需要这样启用 wal 模式:
1 2 3 4 | |
显然,这非常不 pythonic。如果我们使用 sqlite-utils,就可以直接这样启用 wal 模式:
1 2 3 4 5 | |
再回到之前的多线程读写问题。sqlite 在开启 wal 模式后,就可以支持并发读写了。但是,如果你跨线程共享 connection 对象,还是需要加锁互斥才行。在这种情况下,我们可以引入一个线程本地封装:
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | |
1 2 3 4 5 6 7 | |
通过这个封装,我们暴露了一个全局、惟一的 db 对象,并且允许它在多个线程中,不加锁即可使用。原因是,我们利用线程本地存储(Thread Local Storage, TLS),为每个线程维护了一个独立的数据库连接。
然后,我们通过改写__getitem__方法,把对表的访问,代理到当前线程的数据库连接上,从而你可以使用 与 sqlite-utils 文档中记录的完全一致的方法来进行数据库操作。
Semi-ORM¶
在 python 中进行数据库操作,可以用原生方式和 ORM 方式。原生方式性能高,但需要熟悉 sql 语法,并且重构不方便;orm 方式允许我们以更接近 python 的语法去操作数据库。这方面的代表是 sqlalchemy。
不过 sqlalchemy 也有自己的问题,就是它太全面、太复杂了。如果只是一个简单的、探索式的应用,使用 sqlalchemy 就显得有些笨重。
这就是许多人选择 sqlite-utils 的原因。sqlite-utils 解决了以下问题:
- 它是一个半 orm,既允许你以 pythonic 的方式来操作数据库,又不像 sqlalchemy 那么繁琐。
- sqlite 只有数据库引擎,并没有数据管理工具。如果你要知道某个 sqlite 数据库中有哪些表、表的数据如何,还得先编程把它读出来。sqlite-utils 通过 cli 方式提供了这种能力。
Tip
另一个管理 sqlite 数据库的工具是通过 notebook,加上 sqlite-utils 库,或者使用 jupysql 来进行管理。前提也是你要先开启数据库的 wal 模式,这样才能在多个进程间,共享一个数据库。
在 sqlalchemy 中,要拿到数据,你必须先学会如何定义 schema:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | |
这里引入了 Base, Column, String, Float, Interger 等类型,以及,你还得知道魔术字__tablename__的用法。
但在 sqlite-utils 中,这一切则是如此简单:
1 2 3 | |
1 2 3 4 5 6 7 8 9 | |
简直不可思议!你无须定义表结构,就可以直接插入数据!
第一行,我们创建了一个内存数据库,并且建立了连接。如果传入文件名,则是创建了一个磁盘文件数据库。
第二行,我们通过 db["users"] 来引用了现在还不存在的表 -- users,然后直接插入了两条数据。
第三行,我们打印出当前数据库中的所有表格;现在 users 已经存在了。
第四行,我们打印出了表 users 中的列字段,这也是 sqlite-utils 自动为我们判断并创建的表结构。
第五行,我们打印出了表 users 中的所有数据。
sqlite-utils 巧妙地借用了文档数据库(如 MongoDB)的语法,将数据库操作变得异常简单。这样一来,很有可能会涉及到新增字段,或者变更字段定义。但是,如果你的数据应该放在 sqlite 中,那么,新增或者修改字段定义的情况并不会很多,所以,为何不省去繁琐的表结构定义,而且直接让 sqlite-utils 来处理这一切呢?
Tip
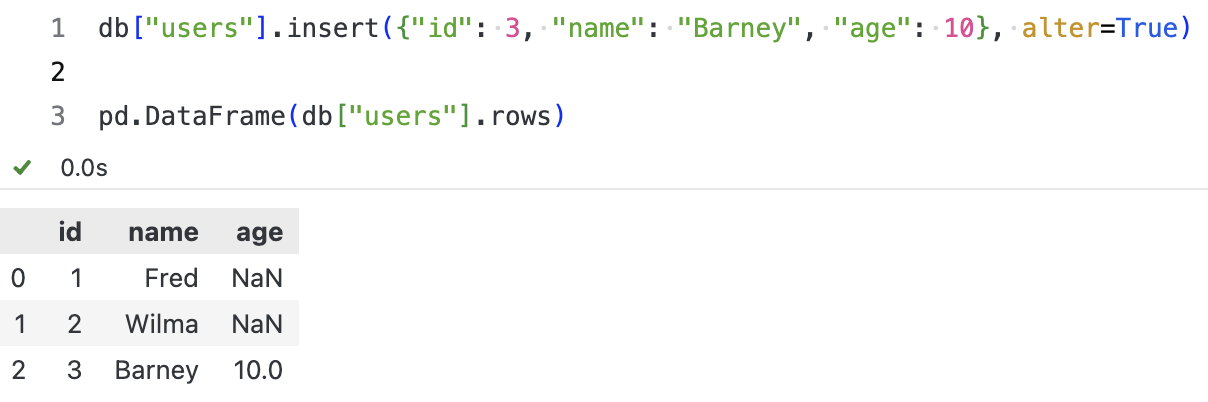
你可能会好奇,如果在第 5 行之后,我们新插入一个对象,该对象包含了性别和年龄字段,那么,sqlite-utils 会如何处理? 在内部,sqlite-utils 会判断表结构发生变化,自动调用 tranform 方法来完成新的表结构定义、数据迁移。请见下图所示。
当然,我们更鼓励显示定义表结构的方法,这样可以提高性能,并且增加数据校验能力。除了在上一篇中介绍的 pydantic 的 models 方法之外,如果你已经很熟悉 dataclasses,那么我们还可以介绍一种基于 dataclasses, 学习起来更容易的手作 ORM 方法。
用 dataclass 定义实体关系映射¶
刚刚演示的 sqlite-utils 示例,我们展示了如何直接从数据库中读取数据,而无需定义表结构。这在探索性的数据分析中非常方便。
但在实际应用中,我们更倾向于显式地定义表结构,并且增加数据类型校验和转换的能力,这样上层调用者的代码才会更简单一致。这就是 dataclass 派上用场的地方。
1 2 3 4 5 | |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | |
在这里有几个小技巧。
第一,我们把类型声明转换为数据库字段(而不是像 sqlalchemy 那样需要显示声明),这非常 pythonic。在_dataclass_to_schema 方法中,我们提取了 User 类的所有字段(不含魔术字段)的类型,如果它是联合类型,就找到第一个非 None 类型作为字段类型;然后,将它们映射为数据库字段类型。当然,由于数据库字段类型有限,多数数据类型被映射为了 TEXT。
第二,我们通过__table__、pk、indices 等魔术字段,为创建表提供元数据。这样就非常像 sqlalchemy 了,但是我们只使用了标准、内置语法,看起来简洁很多。
第三,一些 Python 数据类型被映射成为了数据库中的整数和字符串类型。我们从数据库中读取到的,也会是字符串和整数类型,但它们实际上对应着 datetime 或者 Enum 类型。在支持复杂数据类型的数据库中,数据库连接驱动会自动为我们进行转换。
内置的 sqlite 模块和 sqlite-utils 都不会这样做。但实际上这个转换非常容易,我们完全可以自己来做。如注释❷和❸所示,我们通过__post_init__方法来实现了这一点。
在注释❹中,我们显式地创建了表格,声明了主键和索引。如果不这样,接下来的插入语句就会失败,因为 sqlite-utils 无法将 Gender 类型映射为数据库字段。
未完待续
第四,当我们要保存一个 python 对象时,只要它是一个 dataclasss 类,我们就可以通过类似db["users].insert(asdict(user))一样的方法来保存它。asdict是 dataclasses 中的一个方法,用来将 dataclass 转换为字典类,而 sqlite-utils 会将字典转换为表格中的一行,再插入到数据库中。
注释❺演示了如何读取数据库记录的一种方法,即通过rows。它是一个迭代器,要获取具体的某个元素,我们需要先转换为列表,再通过下标来获取。这样得到的数据也是一个字典,通过User(**dict)可以将其转换为 User 对象,并且,在这个转换过程中, __post_init__方法被调用,从而将 birth 从数据库中的字符串转换为 Python 的日期对象,以及将 gender 从整数转换为 Enum 类型。
这一部分,跟我们本系列上一篇中介绍 Pydantic 的部分有思想上相似之处,只不过这次我们改用了 dataclasses 来与 sqlite-utils 来组 CP。
在所有能使用内置语法的地方,我更喜欢只用内置语法,而不使用第三方。如无必要,勿增实体。

sqlite-utils 增删改查¶
这部分比较简单,我们通过以下代码示例进行说明:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 | |
数据库操作从未如此简单,不是吗?而且加上我们前面实作的廖廖数行 ORM 机制之后,我们可以存储对象、让查询返回对象。
另外,不知道你注意到没有,注释❶中,我们将查询结果转换为了 DataFrame,这里也可以转换成为 polars 的 DataFrame。
将偷懒进行到底¶
优秀的程序员都是懒惰的。他们不喜欢重复劳动,也不喜欢写重复的代码。他们喜欢用简单的方法来解决复杂的问题。如果你也是这一类,那么很可能还在寻求进一步的封装。
为此,Jeremy 教授为你带来了 fastlite -- fast 系列中的新成员。它在 sqlite-utils 之上,引入了 dataclass (就像我们这里所做的一样),另外,它拓展了查询语法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | |
当然,尽管 fastlite 非常直观,学习成本很低,不过在使用之前,你也可以思考一下,是否真的需要它。毕竟,sqlite-utils 已经提供了足够简洁和丰富的功能。
写在 2025 年封底¶
敲下这段文字时,2025 年的沙漏只剩下最后 4 小时。2025 的这本书,也写到了最后一页。
这两天,Manus 被 Meta 收购的消息刷屏了互联网。很多人还记得 Manus 刚发布时的争议——加密货币、邀请码、并不光鲜的出身。
在我们的刻板印象里,只有出身名门、履历完美的精英学霸,才配定义 AI 的未来。而 Manus 的团队来自武汉,创始人也只出道于一所普通的 985 高校。这种“学历决定论”,在量化圈似乎更为根深蒂固。
直到 Manus 被 Meta 以 20 亿美元天价收购,创始人肖弘一跃成为 Meta 副总裁,这记响亮的耳光或许能让我们重新审视: 究竟是学历定义了能力,还是能力重塑了规则?
同样重塑规则的,还有 PyTorch 的缔造者,Soumith Chintala。
如果看早年的简历,Soumith 简直是“反面教材”:高中读的是普通公立,高考只进了一个不起眼的“二本”。大学毕业申请美国硕士,连投 12 所学校, 全部拒信 。
没有名校光环,他靠着 J-1 签证“硬闯” CMU 做短期访学,才勉强被 NYU 补录。即便身在 NYU,即便那里坐镇着 AI 泰斗 Yann LeCun,他也并非嫡系弟子。毕业后,他满怀憧憬向 DeepMind 投递简历, 一次,两次,三次,全部石沉大海 。
找不到工作,签证即将到期,为了留在美国,他不得不去一家并不知名的小公司做基础测试。
从 2005 年到 2017 年,这是一段漫长的黑暗隧道。
“二本”出身、硕士全拒、大厂不要、签证危机、项目腰斩……整整十二年,他几乎一直在失败。但他手里握着一盏微弱的灯——Torch-7。这是一个基于 Lua 的冷门框架,他像照顾孩子一样,没日没夜地重构它、打磨它。
正是这盏灯,最终照亮了 Soumisth 的前程。他被杨立昆推荐进了 Meta 的 FAIR 实验室,即使最初只带着一个三人的小团队。
后来的故事大家都知道了:2017 年,那个小团队创造了 PyTorch。它像野火一样燎原,成为了全球最受欢迎的深度学习框架。
2025 年,当有人在 Twitter 上把这段“逆袭史”挖出来时,Soumith 只是淡淡地回复了一句: “所有这些都是真的。但我还欠很多人一个感谢。”
他感谢导师 Pierre Sermanet 的善良;感谢 Yann LeCun 在他“几乎看不到出路”时的两次援手。但他感谢更多的,是那些普通的“路人”。
这让我想起热腾仁波切讲过的一个故事:
有个虔诚的信徒去五台山找文殊菩萨。他在客栈遇到一个醉汉,醉汉非拉着他喝酒。信徒严词拒绝:“我是来见菩萨的,怎能破戒?”
醉汉笑了笑:“酒都不喝,怎么见菩萨?”
几天后,信徒一无所获,失望而归。醉汉又出现了,让他顺路带封信。信徒虽不情愿,还是守信地送到了地址——竟然是一个猪圈。
他拆开信,对着那头猪念道:“金刚亥母,你利益众生的时间到了,可以走了。——落款:文殊”
话音刚落,那头猪便往生而去。
原来,菩萨早已见过,只是凡眼未识。
在 Soumith 的生命里,也有这样的“凡人菩萨”:是他的印度老乡 Praveen,默默在幕后写代码的核心工程师;是那对背了一身债、却咬牙支持儿子去追梦的父母;甚至是那个在 Twitter 上花时间整理他故事的陌生人 Deedy。
我们生命中的贵人,往往都是凡人相、众生相。
最后,Soumith 说:“我相信,每一个如今‘坐在成功之上’的人,背后都有很多挣扎。生活从来不会轻轻松松。”
在 2025 的封底,我写下这三个故事。 平凡、坚韧、感恩 ,是它们的注脚,也是我想送给每一位量化人的新年礼物。
感谢这三年来,支持过匡醍(Quantide)的每一个人。
量化是一场孤独的修行,但你不必独自前行。愿 2026 年,我们能遇到更多积极、向上、自我修炼的伙伴。
见天地,见众生,终见自己。
祝大家新年 Alpha 长红。