strategy »
Moonshot is all you need - 红利策略完结篇
我们已分4期介绍和 Moonshot 以及如何实现一个红利策略。本篇是本系列的最后一篇,运用之前的Moonshot回测框架,我们将最终完成红利策略的构建。
因子构建方式
红利策略的核心是股息率。事实上股息率因子最早的资产定价因子之一,在Harvey, Liu & Zhu (2016)等一系列经典论文中,Dividend Yield都是作为估值类因子的重要组成部分,但其显著性总体弱于其他经典因子如市值,P/M等。股息率常出现在现金流稳定的公司,是价值因子的一个侧面,此外从股息收益安全性和管理层信号理论信号理论而言,都可以做出恰当的经济学解释。
从股息收益、资本利得和风险规避三个角度,研报构建了多个因子,这些因子对于股票未来的分红有一定的预测效果。下面先简述因子构建方式,具体因子构建代码放在后文。
每期股息率排名前500(DP) 以及 2年平均股息率的因子标准分(DP2)
含义:高股息的股票未来股息率和每股分红也处于高位。\
计算:股息率的计算在前述系列文章中已有论证,从tushare的接口daily_basic取出股息率字段dv_ttm。2年平均股息率dividend_yield_2y_avg 由一年前的dv_ttm,一年前close,与当前的dv_ttm,close搭配计算。具体计算过程参见代码。
派息率(DPR)
含义:高派息率股票未来分红表现或较难持续,而派息率适中或有利于未来收益。具体来说,若派息率处于低位,或说明公司分红表现欠佳,组合整体收益表现一般;若派息率处于高位,分红行为或难以持续。\
计算:派息率是分红/净利润,也就是派息率 = 股息率 / EP = 股息率 * PE,因此从daily_basic取出pe_ttm * dv_ttm。
市值筛选(总市值 > 50 亿元)
含义:小市值加剧组合整体波动表现。\
计算:tushare的接口daily_basic取出total_mv,单位为万元。
换手波动率
含义:换手率波动率在红利股票池中具有较好的选股能力,引入换手率波动率的低波因子有利于提高组合安全边际。\
计算:tushare的接口daily_basic 自由流通口径 turnover_rate_f 计算近一个月的标准差。
EP 标准分
含义: 根据 EP 分组的估值均值回复较为显著,EP 最大组合估值最低。\
计算: daily_basic 接口中,可以直接使用PE来倒推EP,然后取5年的标准分。
较上一个月分红金额TTM增长
含义: 持续、稳定且具增长性的分红传递了管理层对现金流与盈利质量的信心,有利于长期股东回报与估值稳定。
计算:可用 dv_ttm 与 总市值计算dividend_ttm,随后对比月度变化
股东数量标准分
含义: 当股东数量降低,或是因为有信息优势的投资者吸筹看好未来公司业绩。\
计算: 通过股东户数接口stk_holdernumber获取历史序列计算。
审计意见(剔除非标准无保留)
含义: 非标准审计意见往往提示财务不确定性升高或潜在风险事件。\
计算与口径: 通过审计意见接口fina_audit读取audit_result。
经营现金流资产比(Operating Cash Flow / Total Assets)
含义: 若公司现金流充裕,则有利于维系未来的高分红水平。但若公司现金或现金流紧缺依然选择现金分红,该行为或不可持续,且具有一定风险。\
计算: 取 n_cashflow_act,可通过 cashflow_vip, 与同期 total_assets,使用 balancesheet_vip, 并计算n_cashflow_act / total_assets。
留存收益资产比(Retained Earnings / Total Assets)
含义: 如果用留存收益比总资产来衡量生命周期,在成熟期留存收益资产占比较高,发现股利支付集中在这样的公司。 \
计算: balancesheet_vip 取 undistr_porfit 和 total_assets 字段 ,RETA = undistr_porfit / total_assets。
净利润业绩稳健(np_std)
含义:当期财务收益稳健因子(如过去八期的净利润标准分)较大时,红利股票未来的 ROE 或维持较高水平,因此财务收益稳健因子对公司未来盈利具有一定的预测能力\
计算: income_vip接口取n_income_attr_p,计算过去八期的净利润标准分。
数据准备
本部分代码太多,恕不一一展示。在匡醍研究平台中我们提供了完整、可运行的代码,如果读者对策略验证感兴趣,可以申请加入会员后获取。
回测
我们的回测区间设定为2018年11月30日到2023年11月30日。实际上由于国九条的原因,后续策略的表现会更好,我们会在之后的文章中介绍。
由于本策略使用的数据品种过多,数据清理过程复杂,要变换时间区间进行回测,最好有完善的数据获取框架支持。在这篇文章里,我们暂时就不进一步拓展了。
按照 Moonshot 回测框架的思路,我们要先获取行情数据,构建 Moonshot 实例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22 import sys
sys . path . append ( str ( Path ( "." ) . parent ))
import tushare as ts
from helper import qfq_adjustment
from fetchers import fetch_bars
from store import ParquetUnifiedStorage , CalendarModel
from moonshot import Moonshot
# get candles data
start = datetime . date ( 2018 , 11 , 30 )
end = datetime . date ( 2023 , 11 , 30 )
calendar = CalendarModel ( data_home / "rw/calendar.parquet" )
store_path = data_home / "rw/bars.parquet"
bars_store = ParquetUnifiedStorage ( store_path , calendar , fetch_data_func = fetch_bars )
barss = bars_store . get_and_fetch ( start , end )
barss = qfq_adjustment ( barss , "adj_factor" )
barss . tail ()
这部分代码比较简单,略。完整代码请在星球获取。
接下来,我们就实例化 Moonshot 并且加入因子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60 ms = Moonshot ( barss )
# ADD FACTORS
daily_basic_after = pd . read_parquet ( data_home / "rw/moonshot/daily_after.parquet" )
ms . append_factor (
daily_basic_after , "total_mv" , resample_method = "last"
)
ms . append_factor (
daily_basic_after , "dv_ttm" , resample_method = "last"
)
ms . append_factor (
daily_basic_after ,
"dividend_yield_2y_avg" ,
resample_method = "last" ,
)
ms . append_factor (
daily_basic_after ,
"dividend_yield_2y_avg_noffill" ,
resample_method = "last" ,
)
ms . append_factor (
daily_basic_after , "DPR" , resample_method = "last"
)
ms . append_factor (
daily_basic_after ,
"turnover_rate_f_std" ,
resample_method = "last" ,
)
ms . append_factor (
daily_basic_after ,
"inv_pe_ttm_zscore_5y" ,
resample_method = "last" ,
)
ms . append_factor (
daily_basic_after ,
"dividend_ttm_increase_1M" ,
resample_method = "last" ,
)
# ADD HOLDERS
holder = pd . read_parquet ( data_home / "rw/moonshot/holder_zscore_4y.parquet" )
holder . rename ( columns = { "ts_code" : "asset" }, inplace = True )
ms . append_factor ( holder , "holder_z_score" , resample_method = "last" )
# ADD AUDIT
final_audit_df = pd . read_parquet ( data_home / "rw/moonshot/audit_reserve.parquet" )
final_audit_df . rename ( columns = { "ts_code" : "asset" }, inplace = True )
ms . append_factor ( final_audit_df , "has_audit_reserve" , resample_method = "last" )
# ADD CASHFLOW, INCOME, BALANCE SHEET
n_cashflow_act = pd . read_parquet ( data_home / "rw/moonshot/n_cashflow_act.parquet" )
ms . append_factor ( n_cashflow_act , "n_cashflow_act" , resample_method = "last" )
income_8q_zscore = pd . read_parquet ( data_home / "rw/moonshot/income_8q_zscore.parquet" )
income_8q_zscore . rename ( columns = { "ts_code" : "asset" }, inplace = True )
ms . append_factor ( income_8q_zscore , "profit_z_score" , resample_method = "last" )
balancesheet_asset_profit = pd . read_parquet (
data_home / "rw/moonshot/assets_undistr_profit.parquet"
)
ms . append_factor ( balancesheet_asset_profit , "undistr_porfit" , resample_method = "last" )
ms . append_factor ( balancesheet_asset_profit , "total_assets" , resample_method = "last" )
上述过程中,会引入空值,或者本来就存在空值。在回测之前,我们还要进行数据填充:
1
2
3
4
5
6
7
8
9
10
11
12 ms . data . sort_index ( level = [ 'month' , 'asset' ], inplace = True )
cols_to_ffill = [ 'total_mv' , 'dv_ttm' , 'dividend_yield_2y_avg' , 'DPR' , 'turnover_rate_f_std' ,
'inv_pe_ttm_zscore_5y' , 'dividend_ttm_increase_1M' , 'holder_z_score' ,
'has_audit_reserve' , 'n_cashflow_act' , 'profit_z_score' ,
'undistr_porfit' , 'total_assets' ]
# 在每个 asset 内按时间(month)前向填充
ms . data [ cols_to_ffill ] = (
ms . data . groupby ( level = 'asset' )[ cols_to_ffill ]
. ffill ()
)
接下来,我们按策略要求,先构建股票池,一共有4个条件:
每期股息率排名前500。
连续两年分红。转化为dividend_yield_2y_avg_noffill大于0,其中dividend_yield_2y_avg_noffill指的是dividend_yield_2y_avg计算完后不进行空值填充的结果,如果股票在这一个因子上为空,0,或负值,那显然连续不存在连续2年分红。
过去十年没有审计意见。
市值大于50亿。
1
2
3
4
5
6
7
8
9
10
11
12
13 def stock_pool_filter ( data : pd . DataFrame ) -> pd . Series :
df = data . copy ()
# 股息率前 500 名
dv_rank = df . groupby ( level = "month" )[ 'dv_ttm' ] . transform ( lambda x : x . rank ( method = 'first' , ascending = False ))
cond1 = dv_rank <= 500
cond2 = df [ 'dividend_yield_2y_avg_noffill' ] > 0 # 连续两年有分红
cond3 = df [ 'has_audit_reserve' ] == False # 无审计保留意见
cond4 = df [ 'total_mv' ] >= 500000 # 总市值 > 50亿,总市值单位是 (万元)
flag = cond1 & cond2 & cond3 & cond4
return flag . astype ( int )
函数factor_screen描述核心的选股因子。按照研报的理解,对于在红利股票池有效性显著的指标,将使用指标的标准分;对于有效性偏低的股票,则构建阈值信号描述相关信息。
具体来说包括 4个标准分 和 6个信号事件
1. 两年股息率均值 dividend_yield_2y_avg 越大越好
派息率前5分之一 +1 派息率后5分之一 -1, DPR
经营现金流资产比后5分之一 -1 n_cashflow_act / total_assets
留存收益/资产比后5分之一 -1 undistr_porfit / total_assets
EP 前5分之一的股票+1,EP 后5分之一的股票 -1 inv_pe_ttm_zscore_5y
分红预案日至股东大会公告日之间 由于无数据跳过
最近1月分红TTM增长 +1 dividend_ttm_increase_1M
我们把这个过程封装成函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76 def factor_screen ( data : pd . DataFrame , top_n : int = 30 ) -> pd . Series :
df = data . copy ()
# 只对上一层筛选通过的股票打分
if 'flag' in df . columns :
df = df [ df [ 'flag' ] == 1 ] . copy ()
factor_rank_info = {
'dividend_yield_2y_avg' : True ,
'profit_z_score' : True ,
'holder_z_score' : False , # 越小越好
'turnover_rate_f_std' : False , # 越小越好
}
def zscore_func ( s , is_positive ):
s = s . copy ()
if not is_positive :
s = - s
mean = s . mean ( skipna = True )
std = s . std ( skipna = True )
if pd . isna ( std ) or std == 0 :
return pd . Series ( 0 , index = s . index )
z = ( s - mean ) / std
return z . fillna ( 0 )
# 计算财务比率
df [ 'undistr_ratio' ] = np . where ( df [ 'total_assets' ] == 0 , np . nan , df [ 'undistr_porfit' ] / df [ 'total_assets' ])
df [ 'cf_ratio' ] = np . where ( df [ 'total_assets' ] == 0 , np . nan , df [ 'n_cashflow_act' ] / df [ 'total_assets' ])
# 派息率前5分之一+1 派息率后5分之一 -1, DPR
df [ 'score_dpr' ] = df . groupby ( 'month' )[ 'DPR' ] . transform (
lambda s : (
( s >= s . quantile ( 0.8 )) . astype ( int ) - # 前 20% → +1
( s <= s . quantile ( 0.2 )) . astype ( int ) # 后 20% → -1
) . fillna ( 0 )
)
# EP 前5分之一+1 EP 后5分之一-1 inv_pe_ttm_zscore_5y
df [ 'score_ep' ] = df . groupby ( 'month' )[ 'inv_pe_ttm_zscore_5y' ] . transform (
lambda s : (( s >= s . quantile ( 0.8 )) . astype ( int ) - ( s <= s . quantile ( 0.2 )) . astype ( int )) . fillna ( 0 )
)
# 经营现金流资产比后5分之一 n_cashflow_act / total_assets -1
df [ 'score_cf' ] = df . groupby ( 'month' )[ 'cf_ratio' ] . transform (
lambda s : ( - 1 * ( s <= s . quantile ( 0.2 ))) . fillna ( 0 ) . astype ( int )
)
# 留存收益/资产比后5分之一 -1 undistr_porfit / total_assets
df [ 'score_undistr' ] = df . groupby ( 'month' )[ 'undistr_ratio' ] . transform (
lambda s : ( - 1 * ( s <= s . quantile ( 0.2 ))) . fillna ( 0 ) . astype ( int )
)
# score_dividend_increase
df [ 'score_dividend_increase' ] = df [ 'dividend_ttm_increase_1M' ] . fillna ( False ) . astype ( int )
for fac , is_positive in factor_rank_info . items ():
df [ f " { fac } _score" ] = df . groupby ( 'month' )[ fac ] . transform ( lambda s : zscore_func ( s , is_positive ))
# 总分
score_cols = [ f " { fac } _score" for fac in factor_rank_info ] + [
'score_dpr' , 'score_cf' , 'score_undistr' ,
'score_ep' , 'score_dividend_increase' ]
df [ 'total_score' ] = df [ score_cols ] . sum ( axis = 1 )
# Top-N flag
flag = df . groupby ( 'month' )[ 'total_score' ] . transform (
lambda s : ( s . rank ( method = 'first' , ascending = False ) <= top_n ) . astype ( int )
)
# 对齐回原索引(未筛选股票置 0)
flag = flag . reindex ( data . index ) . fillna ( 0 ) . astype ( int )
return flag
接下来,我们就进行筛选和回测:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18 from IPython.display import clear_output
ms . screen ( stock_pool_filter , data = ms . data )
ms . screen ( factor_screen , data = ms . data , top_n = 30 )
ms . calculate_returns ( True )
# 沪深300
pro = ts . pro_api ()
hs300 = pro . index_daily ( ts_code = '000300.SH' ,
start_date = start . strftime ( "%Y%m %d " ),
end_date = end . strftime ( "%Y%m %d " ))
hs300 . index = pd . to_datetime ( hs300 [ "trade_date" ])
benchmark = hs300 [ "close" ] . resample ( 'M' ) . last () . pct_change ()
output = get_jupyter_root_dir () / "reports/moonshot-5.html"
ms . report ( "html" , benchmark = benchmark , output = output , periods_per_year = 12 )
clear_output ()
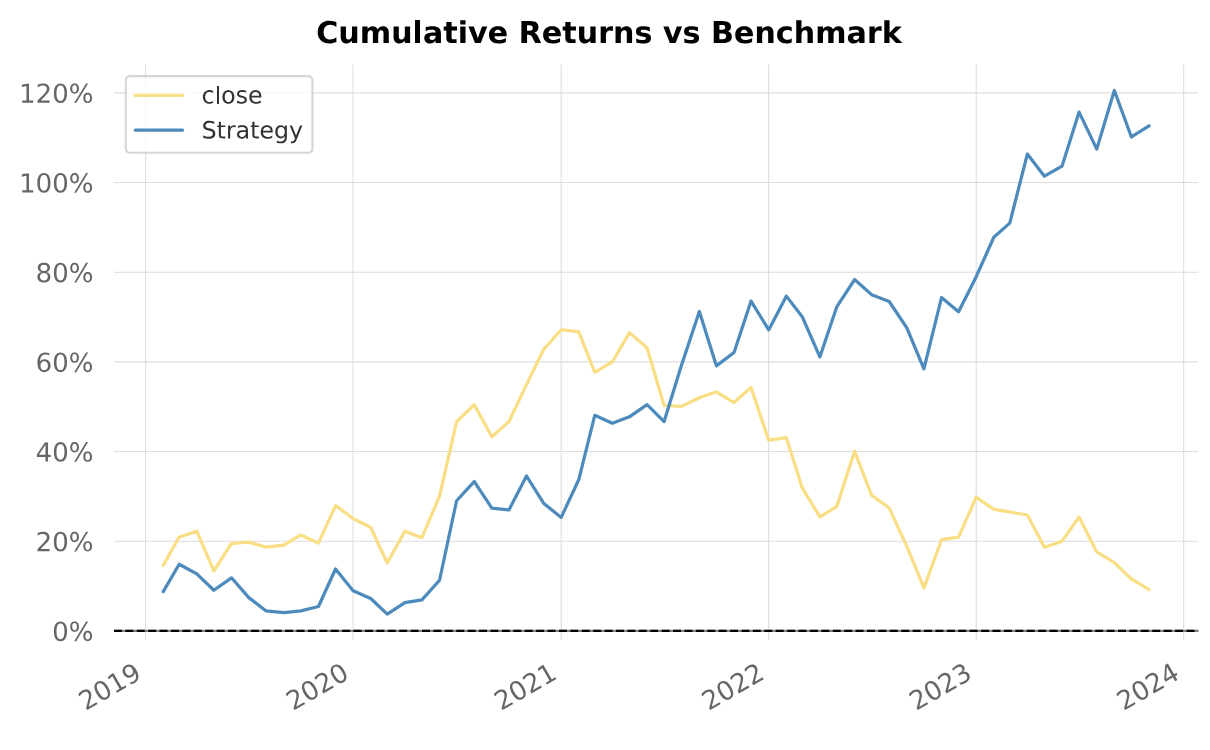
你可以找到 strategy.html 以查看完整的回测报告。与沪深300对照,红利策略显示出巨大的优势。这是两者的累积收益对照图:
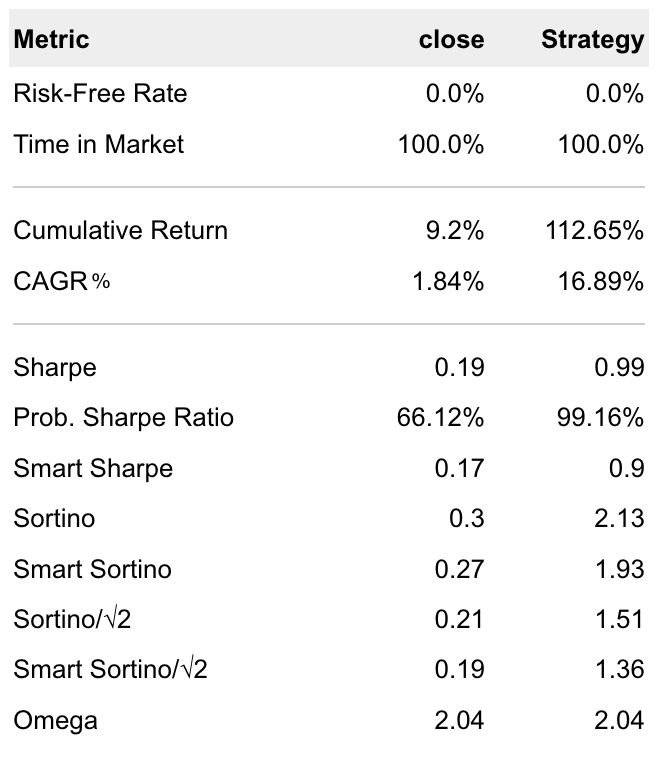
这是一些重要的策略评估指标对照:
5年来,红利策略的累计收益是112.65%,而沪深300只有9.2%。红利策略的年化达到了16%;同期沪深300只有1.84%。
这个策略对标中证红利指数,表现又当如何?
dividend_index = pro . index_daily ( ts_code = '000922.CSI' ,
start_date = start . strftime ( "%Y%m %d " ),
end_date = end . strftime ( "%Y%m %d " ))
dividend_index . index = pd . to_datetime ( dividend_index [ "trade_date" ])
benchmark = dividend_index [ "close" ] . resample ( 'M' ) . last () . pct_change ()
ms . report ( "metrics" , benchmark = benchmark , periods_per_year = 12 )
可以看到,本策略在所有指标上的表现都远远超过了中证红利指数。