The Sound of Risk! 闻弦歌而知雅意, 声音里隐藏的另类因子
最后更新: 2026-04-17
Table of Content

总在为『卷』因子发愁?那是你脑洞还没有打开。
很多人分析财报电话会,第一反应都是看文字稿。
公司说了什么,管理层用了哪些词,语气积极还是保守,LLM 能不能从中挖出情绪信号。这个方向当然有价值,但问题也很现实:文字是可以精心设计的。
尤其是上市公司的公开沟通,很多话都是提前打磨过的,圆滑、稳健、滴水不漏。
即使公司目前遭遇重大经营困难,公司高层一般也总是要传递正面积极的信号。有时候这是出于不得已,因为一旦公司自己承认、唱衰自己,就很容易引起联锁反应,引发不可承受的后果。
所以,我们常常看到,某公司明明正在谋划重大技术转型,却也要死咬着『现有技术是断层领先的』。
那要如何捕捉这种弦外之音呢?
今天为大家介绍一个新思路,来自论文《The Sound of Risk: A Multimodal Physics-Informed Acoustic Model for Forecasting Market Volatility and Enhancing Market Interpretability》
作者换了一个思路:既然“说什么”可以包装,那不如看看“怎么说”。
更具体一点,他们不只分析财报电话会的文字内容,还去分析高管说话时的声音信号,比如紧张、波动、稳定性、激动程度这些更难伪装的线索。
这也是我读这篇论文时最上头的地方。它问了一个非常好的问题:
如果台词本身越来越像公关作品,那市场真正该听的,到底是什么?
论文给出的回答,不在文字里,而在声音里。
1. 为什么要研究这个方向?¶
第一层原因,是传统文本分析已经快被做透了。
财报电话会、股东信、新闻稿,这几年几乎都被 NLP 扫了一遍。从情绪词典到 BERT,再到今天的 LLM,大家都在研究“管理层说了什么”。这个方向当然有价值,但它有一个绕不过去的问题:
公开文本是最容易被精修的。
电话会前半段的 prepared remarks,本来就是会被法务、IR、管理层反复打磨的产物。你可以从中读出态度,但很难保证读到的是“真实状态”。
第二层原因,是财报电话会恰好有一个天然的“露馅时刻”。
那就是 Q&A。
照稿念的时候,谁都能稳。分析师追问的时候,就不一定了。尤其是被问到指引、库存、需求、毛利率、监管、资本开支这些容易出雷的点时,高管的反应往往会从“准备好的表达”切换成“临场处理”。
这时候,文字还能维持体面,声音却未必配合。
第三层原因,是技术条件刚好成熟了。
如果这是十年前,研究者大概率只能提 MFCC、音高、能量、停顿这些手工声学特征,噪声一大就废了。但这几年,wav2vec 2.0、Conformer、WavLM 这一代语音模型起来之后,大家第一次有机会从低质量电话音频里,稳定地学到更高层的表示。
换句话说,过去大家不是没怀疑过“声音里可能有东西”,而是以前直觉有了,工具不够;现在工具终于跟上了。
所以这篇论文最像什么?
不是作者突然灵光一闪,发明了一个玄学方向;而是几个条件刚好在同一时间凑齐了:
- 文本信号越来越拥挤
- Q&A 场景天然带压力测试属性
- 语音基础模型终于能处理这类任务
这三件事叠在一起,才让“从声音里找风险”这件事,从一个酒桌直觉,变成一个可研究的问题。
这也是量化研究员职业生涯可以保持常青的一个重要来源:你知道什么方向是有价值的,然后静静地等待技术成熟带来的范式革命,然后抢先一步抓住机会。
## 2. PIAM 声学模型
论文研究了 2018 到 2023 年间 283 家纳斯达克公司的 1795 场财报电话会,总时长接近 1800 小时。它把三类东西放到了一起:
- 原始音频
- 转写文本
- 金融市场数据
然后搭了一个多模态框架,核心名字叫 PIAM,Physics-Informed Acoustic Model,也就是“带物理约束的声学模型”。
PIAM 的底层并不只是一个普通的语音识别模型,它引入了非线性声学中的 Westervelt 方程。这么做的本质是:管理层在承压或试图隐瞒信息时,声带会有非线性的生理抖动,这种抖动会叠加在正常的语音信号上。
PIAM 通过物理规律作为正则项(Regularization),能像‘显微镜’一样剔除电话线压缩、麦克风削波(Clipping)带来的伪影,精准捕捉到那一丝‘不真诚’的生理特征。

如果把这套方法讲得不那么学术, 就是只用三步,就可以把大象关进冰箱。
第一步,先从原始语音里抽表示。
这部分思路接近今天常见的自监督语音模型: 先让模型“听”到足够多的声音,再学会把声音映射成有信息量的向量表示。论文里用的是类似 wav2vec 2.0 的思路,再配合 Bi-LSTM 和注意力机制,去抓一句话里最关键的片段。
第二步,不只做转写,而是边听边判断。
PIAM 同时输出三类结果:
- 转写文本
- 声音情绪标签
- 声学事件标签
比如静音、笑声、咳嗽、电话质量变化这类东西,也尽量一起识别。因为这些在电话会里并不是“脏数据”,很多时候它们本身就是线索。
第三步,把声学情绪和文本情绪放进同一个坐标系里。
论文没有停在“开心、紧张、愤怒、害怕”这种离散标签上,而是把两边都映射到一个统一的三维情绪空间 ASL: Affective State Label,三个维度分别是:
Tension,紧张度Stability,稳定度Arousal,激活度
这么做的好处很现实。因为金融建模不喜欢“这句话有点像恐惧”这种说法,它更喜欢:
CFO 在 Q&A 阶段的稳定度均值下降了多少
一旦情绪被映射成连续变量,你就能继续往下算均值、波动、偏度、峰度,以及最关键的阶段切换 delta。
论文还给出了一个有意思的分布图,不同角色,声音与文本表现出来的情绪差值分布:
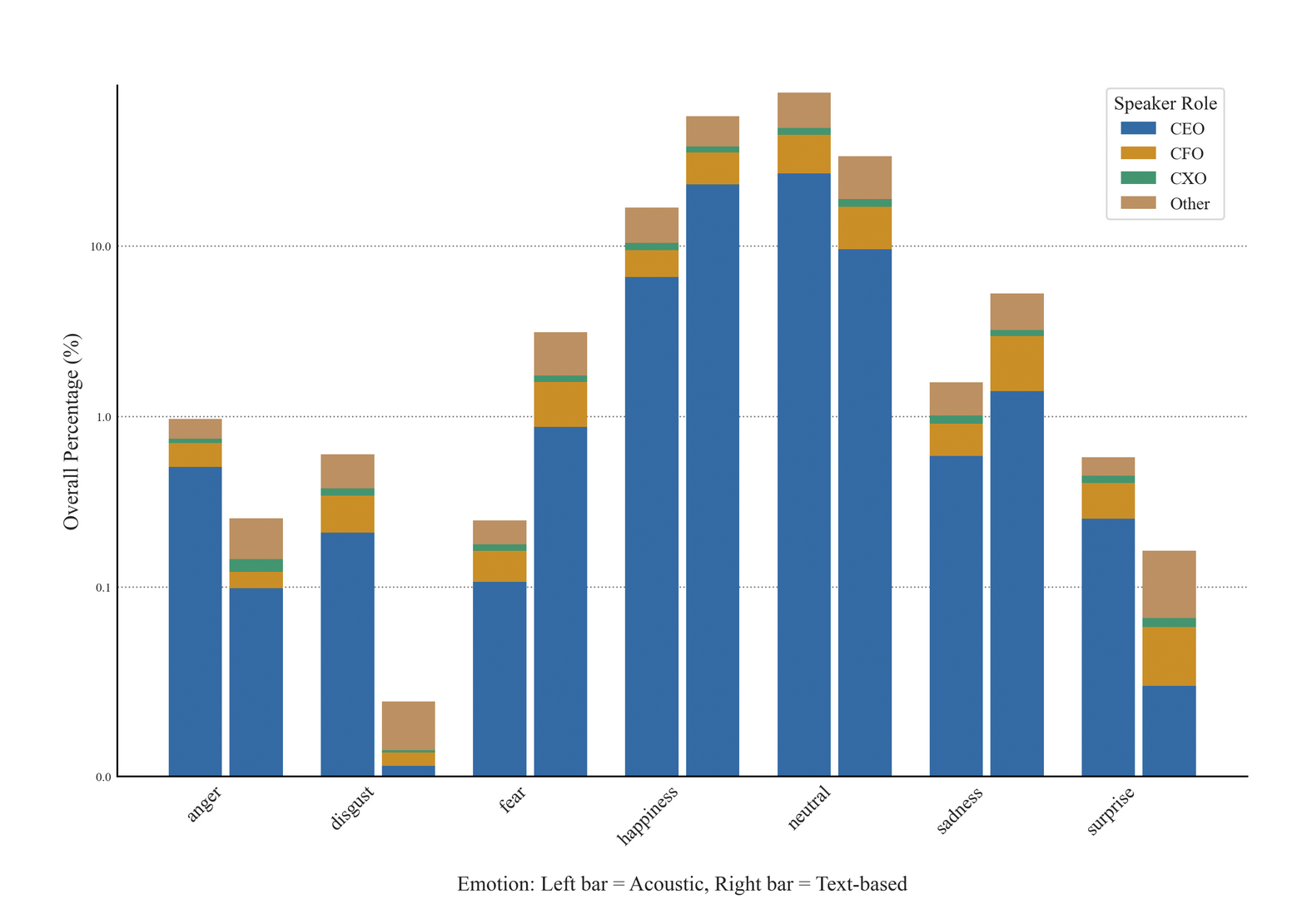
CEO 总是公司里调子最高的那一个人,永远是更加积极。比如,以 anger 为例,尽管他说的话,从文本分析来看,anger 值只有0.1,但从声音分析来看,实际上 anger 值达到了0.8;以happiness 为例,从他说的话来看可能很开心,但从声音分析,其实他并没有那么乐观。
比较有意思的是 CFO。总体上看,他们的情绪值无论是从文本分析还是从声音分析,都比较一致。这也正是这个模型价值所在,一旦 CFO 的声音情绪与文本情绪不一致,这就是信息熵暴增的地方 -- 只有小概率事件发生时,事件才有传播价值。
这个也很合理。CEO 常常负责讲愿景、讲方向、讲叙事;CFO 更容易在问答里被打到那些不能只靠叙事处理的问题,比如库存、现金流、利润率、会计处理、资本开支、指引兑现。
3. 抓住声音的裂隙¶
这篇论文最聪明的一刀,切在了 Q&A一节。
作者没有把整场电话会当成一个统一文本块去算情绪,而是很认真地区分了两段:
- prepared remarks
- analyst Q&A
这个切分太重要了。
因为这两段根本不是同一种信息。
前者更像新闻发布会,后者更像压力测试。
前者看的是“公司想传达什么”,后者看的是“公司在被追问时还稳不稳”。
于是论文盯住了一个非常有意思的地方:
高管从照稿发言切换到临场问答时,情绪有没有发生明显变化?
这其实比“整场电话会平均情绪偏正面还是偏负面”有意思得多。
平均值太容易被前半段平滑掉了。真正有信息量的,往往是切换瞬间的波动。
4. 被量化的情绪波动¶
所以,这篇文章是一个预测模型吗?那也没有这么简单。
它最重要的结论,不是“高管声音紧张,所以股价要跌”,而是一个更细、更像真的结论:
声音和文本里的情绪信号,对“未来收益方向”帮助不大,但对“未来波动率”帮助很大。
这点特别关键。
很多人一看到这种研究,直觉都是: 那是不是能靠听电话会预测明天涨跌?
论文的答案基本是否定的。
但它在另一件事上很强: 预测未来一段时间市场会不会更不安。
具体来说:
- 对未来收益方向,模型几乎没有稳定预测力
- 对未来波动率,模型表现明显更好
- 在预测 30 天已实现波动率时,完整多模态模型的样本外
R²达到0.438 - 传统金融因子基线模型大约是
0.251
这个差距不算小。
如果把它翻译成人话,就是:
听高管怎么说,未必能告诉你“股票明天涨不涨”;但很可能能告诉你“接下来这只票会不会更折腾”。
这也是为什么我觉得这篇论文并不玄。
方向本来就极难预测,外生变量太多;但“不确定性有没有在抬头”,往往更容易从管理层状态里泄露出来。
市场很多时候不是怕坏消息,怕的是不知道到底还有多少坏消息没说出来。
从这个角度看,论文抓住的不是“坏结果”,而是不确定性本身的提前升温。
对于期权交易者来说,能够预测出波动率变化,这正是他们寻找的“圣杯”。涨跌是“矢量”,波动率是“标量”。在金融衍生品市场,标量是可以直接交易的资产。PIAM 模型的价值就在于它提供了一个比市场共识更早、更准的“不确定性度量衡”。
5. 物理约束¶
模型的第二步,物理约束的正则化,是论文里最技术、也最容易把读者看跑的一段,但其实背后的直觉不复杂。
作者认为,财报电话会音频的问题,不只是普通噪声,更常见的是非线性失真。比如:
- 麦克风过载,声音削波
- 电话系统压缩太狠,细节变形
- 低码率传输带来伪影
如果你把这些都当成“随机噪声”,模型可能会把电话系统的毛病学成情绪特征。
所以论文借用了非线性声学里的 Westervelt 方程,把它做成一个正则项,去约束模型的潜在表示别太离谱。
一句话解释就是:
声音不是纯数字,它背后有发声和传播的物理过程。既然电话会音频的失真有规律,那模型最好知道一点物理常识。
这个想法放在流体、气象、材料里已经不新鲜了,放到财报电话会里就显得很新。
6. 爆裂无声¶
我对这篇论文真正着迷的地方,不是多模态,也不是 physics-informed 这几个词本身。
而是它抓住了财报电话会这个场景里最尴尬、也最真实的一点:
这是一个高度表演化的场合,但又不可能百分之百表演到底。
稿子可以提前练,词可以提前挑,风险提示可以提前写。
但一旦进入问答,一些细小的裂缝还是会漏出来。 沉默、发紧、节奏乱掉、稳定度下降、激活度异常抬高。
这就是为什么 The Sound of Risk 会让我想到 The Sound of Silence。
沉默也是一种态度。现在我们可以学习和预测了。
前者讲的是风险有了声音,后者讲的是声音背后藏着沉默。放到财报电话会里,这两件事刚好会在同一个时刻发生:
你的沉默可以震耳欲聋;你的发声也可以苍白无力。
参考链接:
[1] https://arxiv.org/html/2508.18653v1